Archive for the ‘SOA’ Category
 Starter SOA
Starter SOA
Jeff Schneider has posted a series of entries on “Starter SOA” on his blog. The first deals with what he “believes is at the heart of the SOA issue.” It recommends attacking three specific areas in getting started: portfolio management, enterprise architecture, and information management. I think this is right on, for very straightforward reasons. First, portfolio management deals with what services should be created. If you don’t make any changes to this discipline, you’re simply going to get the same solutions you always have, except with some services thrown in. That’s not SOA. Secondly, enterprise architecture is the technical counterpart to the portfolio management side. While portfolio management is concerned about the business aspects of shared services, enterprise architecture needs to be concerned about the technical aspects of shared services. Finally, information management is the source of consistency across our services. If every service team defines its own service schemas, we really haven’t made things much better, as additional effort must now be made to mediate between the information models of every consumer and every service that must talk to each other. Get two or more services and consumers involved, and it simply increases in complexity.
In the next entry, Jeff discusses the fact that SOA will challenge the organizational structure of SOA. How are organizations supposed to address these challenges? He suggests forming an SOA Steering Committee. The committee consists of a cross-discipline team of people who are normally thinking in enterprise terms, rather than project-specific. Importantly, however, he emphasizes that this committee must interact with their project-specific counterparts. That is, the enterprise architect works with application architects. The portfolio analyst works with the project analyst. The PMO rep works with the project manager, and so on. An important aspect of this group is that they can make enterprise decisions as things progress with SOA. An enterprise architect trying to drive SOA on his or her own isn’t left trying to find an open ear when they determine that organizational change is needed, or that a project should be split into multiple projects.
In part 3 (I don’t know if he has more parts planned!), he gets into a more sensitive and difficult area: money. The most important thing that he introduces here is the simple notion that the funding model has to change. Where funding was previously all about getting the “application” completed, we now need models that fund shared items- shared services, shared infrastructure. This shouldn’t be new to organizations, as shared infrastructure is certainly something that they should be dealing with today, this now just extends it into the application development domain.
It’s good to get back to the basics every now and then. Those of us that are out there commenting on this on a regular basis can get into modes where the only other people who care about what we’re saying are other commentators, and not everyone is at that point.
Metrics, metrics, metrics
James McGovern threw me a bone in a recent post, and I’m more than happy to take it. In his post, “Why Enterprise Architects need to noodle metrics…” he asks:
Hopefully bloggers such as Robert McIlree, Scott Mark, Todd Biske and others would be willing to share not only successes within their own enterprise when it comes to metrics but also any unintended consequences in terms of collecting them.
I’m a big, big fan of instrumentation. One of the projects that I’m most proud of was when we built a custom application dashboard using JMX infrastructure (when JMX was in its infancy) for a pretty large web-based system. The people that used it really enjoyed the insight it gave them into the run-time operations of the system. I personally didn’t get to use it, as I was rolled onto another project, but the operations staff loved it. Interesting, my first example of metrics being useful comes from that project, but not from the run time management. It came from our automated build system. At the time, we had an independent contractor who was acting as a project management / technical architecture mentor. He would routinely visit the web page for the build management system and record the number of changed files for each build. This was a metric that the system captured for us, but no one paid much attention to it. He started posting graphs showing the number of changed files over time, and how we had spikes before every planned iteration release. He let us know that those spikes disappeared, we weren’t going live. Regardless of the number of defects logged, the significant amount of change before a release was a red flag for risk. This message did two things: first, it kept people from working to a date, and got them to just focus on doing their work at an appropriate pace. Secondly, I do think it helped up release a more stable product. Fewer changes meant more time for integration testing within the iteration.
The second area where metrics have come into play was the initial use of Web Services. I had response time metrics on every single web service request in the system. This became valuable for many reasons. First, because the thing collecting the new metrics was new infrastructure, everyone wanted to blame it when something went wrong. The metrics it collected easily showed that it wasn’t the source of any problem, and actually was a great tool in narrowing where possible problems were. The frustration switched more to the systems that didn’t have these metrics available because they were big, black boxes. Secondly, we caught some rogue systems. A service that typically had 200,000 requests per day showed up on Monday with over 3 million. It turns out a debugging tool had been written by a project team, but that tool itself had a bug and started flooding the system with requests. Nothing broke, but had we not had these metrics and someone looking at them, it eventually would have caused problems. This could have went undetected for weeks. Third, we saw trends. I looked for anything that was out of the norm, regardless of whether any user complained or any failures occurred. When the response time for a service had doubled over the course of two weeks, I asked questions because that shouldn’t happen. This exposed a memory leak that was fixed. When loads that had been stable for months started going up consistently for two weeks, I asked questions. A new marketing effort had been announced, resulting in increased activity for one service consumer. This marketing activity would have eventually resulted in loads that could have caused problems a couple months down the road, but we detected it early. An unintended consequence was a service that showed a 95% failure rate, yet no one was complaining. It turns out a SOAP fault was being used for a non-exceptional situation at the request of the consumer. The consuming app handled it fine, but the data said otherwise. Again, no problems in the system, but it did expose incorrect use of SOAP.
While these metrics may not all be pertinent to the EA, you really only know by looking at them. I’d much rather have an environment where metrics are universally available and the individuals can tailor the reporting and views to information they find pertinent. Humans are good at drawing correlations and detecting anomalies, but you need the data to do so. The collection of these metrics did not have any impact on the overall performance of the system, however, they were architected to ensure that. Metric collection should be performed as an out-of-band operation. As far the practice of EA is concerned, one metric that I’ve seen recommended is watching policy adherence and exception requests. If your rate of exception requests is not going down, you’re probably sitting off in an ivory tower somewhere. Exceptions requests shouldn’t be at zero, either, however, because then no one is pushing the envelope. Strategic change shouldn’t solely come from EA as sometimes the people in the trenches have more visibility into niche areas for improvement. Policy adherence is also needed to determine what policies are important. If there are policies out there that never even come up in a solution review, are they even needed?
The biggest risk I see with extensive instrumentation is not resource consumption. Architecting an instrumentation solution is not terribly difficult. The real risk is in not provided good analytics and reporting capabilities. It’s great to have the data, but if someone has to perform extracts to Excel or write their own SQL and graphing utilities, they can waste a lot of time that should be spent on other things. While access to the raw data lets you do any kind of analysis that you’d like, it can be a time-consuming exercise. It only gets worse when you show it to someone else, and they ask whether you can add this or that.
Why SOA?
I’ve been meaning to post an entry on this for some time now. Back in early February, Joe McKendrick had a post entitled “A CTO underwhelmed by SOA.” I recently had a conversation with a CIO (not specifically on SOA) who lamented that we’re still solving the same old problems. A google search on “trough of disillusionment” and “SOA” yields about 12,000 hits. So why are we doing SOA?
If you’ve seen my bio at a conference, or looked at my “About Me” page here, you’ll know that I’ve always been interested in human computer interaction and usability. Why? It’s because I’ve always felt that the user interface can be a differentiator. While that was probably more the case in the early 90’s during my graduate school days, I do think that it still holds true today. So how did I make the switch to being such an advocate of SOA? Largely, it was for very similar reasons. I looked at SOA and felt that if done properly, it could be a differentiator to the bottom line. While you could argue that the Web did the same thing, that whole craze was far more about using Java and J2EE than about changing the business. The best thing about SOA is that the discussion has been dominated by SOA and not by underlying technologies.
So how can SOA be a differentiator? Well, here’s a recent case study that was published. Yes, it’s a classic problem of getting that single view of the customer in the hands of the people that need it most. What’s great about this case study it clearly shows the difference between the monolithic application world (they had to have the Data Warehouse operators generate an Excel-based extract) to the world of SOA (the applications they use pulled it from the data warehouse directly via services). Break down those application walls, and start viewing things in a bigger picture. While the hype is going down, there are still plenty of opportunities available. Keep in mind, however, that the business strategy should be the driver of where your SOA efforts are focused. Kudos to the person at Helzberg that recognized that they needed to make customer information available at any store. That was the business need, and it gave them an excellent opportunity to leverage SOA appropriately.
EDA begins with events
Joe McKendrick asks, “Is EDA the ‘new’ SOA?” First, I’ll agree with Brenda Michelson that EDA is an architecture that can effectively work in conjunction with SOA. While others out there view EDA as part of SOA, I think a better way of viewing it would be that services and events must both be part of your technology architecture.
The point I really want to make however, which expounds on my previous post, is that I simply think event-oriented thinking is the exception, rather than the norm for most businesses. I’m not speaking about events in the technical sense, but rather, in the business sense. What businesses are truly event driven, requiring rapid response to change? Certainly, the airlines do, as evidenced by JetBlue’s recent difficulties. There are some financial trading sectors that must operate in real-time, as well. What about your average retail-focused company, however? Retail thinking seems to be all about service-based thinking. While you may do some cold calls, largely, sales happen when someone walks into the store, goes to the website, or calls on the phone. It’s a service-based approach. They ask, you sell. What are the events that should be monitored that would trigger a change in the business? For companies that are not inherently event-driven, the appropriate use of events are for collecting information and spotting trends. Online shopping can be far more informative for a company than brick-and-mortar shopping because you’ve got the clickstream trail. Even if I don’t buy something, the company knows what I entered in the search box, and what products I looked at. If I walk into Home Depot and don’t purchase anything, is there any record of why I came into the store that day?
Again, how do we begin to go down the direction of EDA? Let’s look at an event-driven system. The October 2006 issue of Business 2.0 had a feature on Steve Sanghi, CEO of Microchip Technology. The article describes how he turned around Microchip by focusing on commodity processors. As an example, the articles states that Intel’s automotive-chip division was pushing for “a single microprocessor near the engine block to control the vehicle’s subsystems and accessories.” Microchip’s approach was “to sprinkle simpler, cheaper, lower-power chips throughout the vehicle.” Guess what, today’s cars have about 30 micro-controllers.
So, what this says is that the appropriate event-based architecture is to have many, smaller points of control that can emit information about the overall system. This is the way that many systems management products work today- think SNMP. To be appropriate for the business, however, this approach needs to be generating events at the business level. Look at the applications in your enterprise’s portfolio and see how many of them actually publish any sort of data on how it is being used, even if it’s not in real time. We need to begin instrumenting our systems and exposing this information for other purposes. Most applications are like the checkout counter at Home Depot. If I buy something, it records it. If I don’t buy something and just exit the store, what valuable information has been missed that could improve things the next time I visit?
I’d love to see events become more mainstream, and I fully believe it will happen. I certainly won’t argue that event-driven systems can be more loosely coupled, however, I’ll also add that the events we’re talking about then are not necessarily the same thing as business events. Many of those things will never be exposed outside of IT, nor should they be. It’s the proper application of business events that will drive companies opening up their wallets to purchase new infrastructure built around that concept.
What’s the big deal about BPEL
Courtesy of this news release from InfoWorld, I found out that Microsoft Windows Workflow Foundation (WWF, which has nothing to do with endangered animals or professional wrestlers) is going to support BPEL. This is a good thing, but what does it really mean?
I’ll admit that I’ve never gotten very excited about BPEL. My view has always been that it’s really important as an import/export format. You should have a line item on your RFI/RFP that says, “supports import/export of BPEL.” You should ask the sales guy to demonstrate it during a hands-on section. Beyond this, however, what’s the big deal?
The BPM tools I’ve seen (I’ll admit that I haven’t seen them all nor even a majority of them) all have a nice graphical editor where you drag various shapes and connectors around, and they probably have some tree-like view where you draw lines between your input structure and your output structure. At best, you may need to hand code some XPath and some very basic expressions. The intent of this environment is to extract the “business process” from the actual business services where the heavy duty processing occurs. If you sort through the marketing hype, you’ll understand that this is all part of a drive to raise the level of abstraction and allow IT systems to be leveraged more efficiently. While we may not be there yet, the intent is to get tools into the hands of the people driving the requirements for IT- the business. Do you want your business users firing up XML Spy and spending their time writing BPEL? I certainly don’t.
What are the important factors that we should be concerned about with our BPM technologies, then? Repeating a common theme you’ve seen on this blog, it’s the M: Management. No one should need to see BPEL unless you’re migrating from one engine to another. There shouldn’t be a reason to exchange BPEL between partners, because it’s an execution language. Each partner executes their own processes, so the key concern is the services that allow them to integrate, not the behind the scenes execution. What is important is seeing the metrics associated with the execution of the processes to gain an understanding of the bottlenecks that can occur. You can have many, many moving parts in an orchestration. Your true business process (that’s why it was in quotes earlier) probably spans multiple automated processes (where BPEL applies), multiple services, multiple systems, and multiple human interactions. Ultimately, the process is judged by the experiences of the humans involved, and if they start complaining, how do you figure out where the problems are? How do you understand how other forces (e.g. market news, company initiatives, etc.) influence the performance of those processes. I’d much rather see all of the vendors announcing support for BPEL begin announcing support for some standard way of externalizing the metrics associated with process execution for a unified business process management view of what’s occurring, regardless of the platforms where everything is running, or how many firewalls need to be traversed.
IT Conversations Podcast
Ed Vazquez and I were invited to join Phil Windley and Scott Lemon on Phil’s Technometria series within IT Conversations for a discussion on SOA, with quite a bit of detail on SOA Governance. Give it a listen and feel free to follow up with any questions.
You can download the podcast here.
More consolidation: Cisco to acquire Reactivity
The consolidation in the vendor space continues. From tmcnet.com:
Cisco Systems Inc., a leading supplier of Internet network equipment, has announced its intention to acquire Reactivity Inc., a provider of gateway solutions that simplify web services management. The agreement, which is subject to the standard closing conditions, states that Cisco will pay $135 million and assumed options of Reactivity.
Jeff will need to update his scorecard. This certainly puts two big boys head-to-head in this space with IBM previously having acquired DataPower. Cisco has been very quiet for some time regarding its AON technology, so I’m wondering how this acquisition impacts that effort.
The more important question, however, is what this means for the bigger picture. I previously posted on the need for an open, integrated world between service management, service connectivity, and service hosting. Unfortunately, these acquisitions may point more toward single-vendor, proprietary integrations, rather than open solutions. Will the Cisco version of Reactivity still partner with companies like AmberPoint, or will the management focus now shift all to Cisco technologies, starting with the Application Control Engine mentioned in Cisco’s press release? What’s been happening with the Governance Interoperability Framework now that HP owns Systinet? IBM’s Registry/Repository solution doesn’t support UDDI and has a new API.
While bigger fish eating the smaller fish is way things frequently work with technology startups, these players need to keep in mind the principles of SOA. Their products should be providing services to enterprise, and those services should be accessible in an open, standards-based way. Just as the business doesn’t want a bunch of packaged business applications that require redundant data and can’t talk to each other, IT doesn’t want a bunch of infrastructure that requires redundant management capabilities with only proprietary APIs to work with. We need SOA for IT, and any vendor selling in this space should be making that a reality, not making it worse.
The human side of SOA/BPM
Two recent posts that were completely unrelated have prompted me to write a little bit about the human interaction side of SOA and BPM. First, in response to the debate on maturity levels between myself and David Linthicum, Lori MacVittie posted this entry on the F5 DevCentral blogs. She didn’t get into the debate on maturity levels, but rather brought up a point about the use of the term orchestration. She states:
Orchestration of applications is a high level automation mechanism that can’t really be completed until there is a solid underlying SOA infrastructure and set of common services in place. It’s the pinnacle of SOA achievement, the ultimate proof that an organization SOA can indeed provide the benefits touted by pundits. But orchestration of services should also be the mechanism by which applications are constructed.
The second post that caught my eye was Ismael Ghalimi’s post, “What is Wrong with BPM.” In this post, he talks about the problems customers face in selecting a BPM product and some of the things that customers run into after the purchase has been made and they try leveraging the solution on one of their real business problems. He states:
Then comes the really fun part: the business folks want a different user interface for their workflow. The one you got out of the box seems to be working pretty well, and you could display your company logo at the top left, but somehow the suits have something different in mind, and they want it now. They paid $300,000 for some magic pixie dust that gives them business agility, and they expect it to make you a contortionist worthy of a full-time job with Cirque du Soleil. So you end up spending the next six months writing massive amounts of JavaScript code that will hardcode the customer’s process deep into the user interface. You will be late, over budget, and won’t benefit from future software upgrades, for what you have now is built upon a completely different codebase. Great…
The two things I want to call out are Lori’s phrase “orchestration of applications” and Ismael’s laments about the quality of the user interface. I believe both of these posts are hitting on an element that is frequently forgotten around SOA, which is the human interaction. Regardless of how many services you build, some user is still going to need a front end, and there are inherently different concerns involved. Ismael’s absolutely right that some bare bones web form creation tool slapped onto the ugly schemas that represent the process context just don’t cut it. While 5-10 years ago, you may have been able to limp by with basic HTML forms, today’s web UIs involve AJAX, CSS, JavaScript, Flash, and much more. The tools that are calling themselves orchestration engines excel at what Lori calls orchestration of services (the BPEL space), but I don’t know that there are many that are really excelling at business process orchestration. I’m using my definition of business process orchestration here, which is both the human activities and the automated activities. I’m guessing that this is what Lori meant by orchestration of applications, however, I try not to use the term application anymore. It implies a monolithic approach where everything is owned end-to-end, and that simply won’t be the case in the future. If I do use the term, it’s reserved for the human facing component of the technology solution.
True business process orchestration that includes the human element, is not one that we’re seeing a lot of case studies on, but it’s where we need to set our sights. The problem is quite difficult, as the key factor is context. When I was working with a team on a reference solution architecture for BPM technology, one of the challenges was how and when to bring in context. If you rely on events to trigger state transitions, should those events carry references to information, or the contextual information itself? If it contains references, then you need access to all of the associated information stores, and you need to figure out what information is relevant for the problem at hand. It’s hard enough to get this right for an automated system where the information required is probably well defined. Now try getting it right when the events are tied back to a user interface. The problem is that every scenario may require a different set of information. As humans, we’re good at determining correlations and understanding where to go. Systems are not. Our goal should be to creating solutions that support the flexible context required for true business process orchestration. I think this will keep many of us gainfully employed for years to come.
Agile Methods for EA
James McGovern asks, “How come Enterprise Architects don’t embrace agilism?” He asked a number of us to share our experiences about how frequently we talk about agile methods. The first question I asked myself after reading his entry was, “What are we even talking about when we say agile methods for EA?” Agile methodologies have been associated with software development, and while the domain of enterprise architecture does include software development, it is not solely limited to that. So, I went to the agile manifesto and revisited its four values. They are:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiations
- Responding to change over following a plan
So, what does this mean in the context of EA practices? Let’s look at them one at a time. Keep in mind that the original authors of this manifesto state these as preferences, not absolutes. All components have value, the authors simply believe that the items on the left have more value.
Individuals and interactions over processes and tools. This could easily be rephrased as “don’t become an ivory tower.” This is certainly something that all EA teams should keep in mind. If the only meetings you have are with other enterprise architects, there’s a problem. I’m a firm believer that information is power. Too often, we prevent the sharing of information because of fiefdoms that have been set up in the enterprise. Some are formal, some are not. It’s frequently a matter of trust. If you trust that the people you share information with will use it wisely, it gets shared. If you don’t, you don’t share it. Sometimes the lack of trust is justified, sometimes it is not. As far as the manifesto goes, however, the key word is interactions. Interestingly, in James’ post, he states, “Why not optimize the organization so as to reduce the amount of folks one needs to interact with in order to get the job done?” While you may think he’s dismissing interaction, which would be contrary to the manifesto values, I think the message is that you also need to understand your role in the organization. Interaction is important, to a point. As an individual, you need to make good decisions on when to interact and who to interact with. If you don’t, you lose trust and credibility. It’s like the Emotional Bank Account® from Seven Habits of Highly Effective People. As far as how this impacts EA, it really means that you need to get out and work with the people using your reference architectures and your strategic plans.
Working software over comprehensive documentation. Since most of what EA does is create documentation, the thing to look at here is whether the right documentation is being created. Again, the authors of the manifesto don’t say that documentation has no value. Documentation does have value, and EAs need to ensure that their own documents are targeted with purpose, as are the documents they receive. The EA needs to concerned about the items that will live on and be of importance to the enterprise.. The project architect needs to be concerned about the items that make the project successful. The two may not necessarily overlap. This ties back into my comments about roles and responsibilities. Without a clear understanding of roles and responsibilities, how will the project know when to interact with the EA and vice versa. Forcing a formal review process to mandate that some interaction occur is not a solution when the roles, responsibilities, and goals are not well understood. Formal reviews can be powerful, but only where they complement the interactions taking place, rather than replacing them.
Customer collaboration over contract negotiation. No arguments here. Unfortunately, we’re still in the state where the IT / business relationship is seen as customer / supplier, rather than working as partners. It ripples all the way back up to the information sharing, and ultimately, that can have a very negative effect on the solutions. If, as an EA, I’m not aware that the company’s strategy is to grow by acquisition, my focus may be in the wrong area, resulting in the integration costs being much higher than they would have been had I been in the loop.
Responding to change over following a plan. I had someone ask me once, “How do I make sure this service is an enterprise service?” I told that person, “You don’t. Instead, assume that your service will change and understand how you’re going to manage it.” The real problem is that we don’t plan for change to begin with. We think things can be etched in stone once and we’re done. Technology solutions in the enterprise, software development projects in particular, simply don’t work that way. The organization needs to figure out how to include change in their planning processes and accommodate it accordingly. This doesn’t mean throw out your project plans, but it does mean that a single annual review and funding cycle won’t work.
My final comments: Adopting agile methods is kind of like losing weight. Going to an extreme doesn’t work. You need to have moderation, finding the right amounts of each food and each type of exercise for you to be successful. The authors of the manifesto clearly state that they are articulating preferences, not absolutes. You may read James’ post and think that the we need less communication. I don’t believe that. I also don’t believe that more communication is the answer, either. I believe that we need more of the right kind of communication, and less of the wrong kind of communication. If you’re an individual in an enterprise, always ask the questions: Who should I be communicating with and should be communicating with me? Don’t wait for them to come to you and ask for something, and don’t wait for them to come and give you something you think you need. Get out of your chair and do it.
Uptake of Complex Event Processing (CEP)
I’m seeing more and more articles about complex event processing (CEP) these days. If you’ve followed by blog, you’ll know that I’m a big fan of events, so I try to read these when they come across my news reader. One of the challenges I see, however, is that event-driven thinking is not necessarily the norm for businesses. Yes, insurance companies may deal with disaster events, and financial services companies may deal with “life” events like weddings, births, kids going to college, but largely, the view is very service-based. It is reactionary in nature. You ask me for something, and I give it to you.
This poses a challenge for event processing to gain mindshare. While event processing is certainly the norm in user interface processing and embedded systems, it’s not in your typical business IT. Ask yourself- if you were to install a CEP system in your enterprise today, what events would it see?
The starting point that I see for events should merely be publication. Forget about doing anything but collecting statistics at the beginning. Since events don’t align with how we’re normally thinking, perhaps we should let them show us how we should be thinking. This gets into the domain of business intelligence. The beauty of events, however, is that they can make the intent explicit, rather than implicit. If I’m only performing analysis based on database changes, am I seeing the right thing, or am I only seeing symptoms of the event? Not all events may result in a database change, and that’s where the important correlations may lie. If some companies shows up on page one of the Wall Street Journal, it could result in increased trading activity for that company. My databases may record the increased trading, I may not have a record of the triggering event- the news story.
Humans are very good an inferring relationships between events, sometimes better than we think. But without any events, how can we infer any relationships? We don’t want to overwhelm the network with XML messages that no one ever looks at, but we shouldn’t be at the opposite extreme either. Starting with new applications, I’d make sure that those systems are publishing some key events based upon their functionality. Now, we can start doing some analysis and looking for correlations. We then start to encourage event-driven thinking about the business, and as a result, have now created the potential for CEP systems to be used appropriately.
As an example of how far we still have to go, let’s look at Amazon. They certainly leverage business intelligence extremely well. Unfortunately, as far as I can tell, it’s largely based upon tracking the event that impacts their bottom line directly- purchasing. If I were them, I’d be looking at wish list activity much more strongly. Interestingly, my wife gets more recommendations on technical books that I do. Why? Because she’s purchasing them as gifts for me. I put them on my wish list, she buys them. Because they’re looking at the wrong event, they now make an inference that she’s interested in them when she isn’t. I am. They need to track the event of me adding it to my wish list, along with someone purchasing it for me, and then turn around and make recommendations back to me. Of course, that’s part of the challenge, though. There is simply a ton of information that you could collect, and if you collect the wrong stuff, you can waste a lot of time. Start with a small set of information that you know is important to your business and build out from there.
The Scope of SOA Adoption
I just finished giving a webinar on the importance of SOA pilots with Alex Rosen, and I hope the attendees found it informative. One of the things that I discussed in the webinar was the scope of SOA adoption. Given the recent attention to my last post, I thought I’d discuss it a bit more, since it’s one of the two dimensions of the maturity matrix. It’s also what makes the effort more than just a “search and replace” on the SEI CMMI models as one commenter over on InfoWorld thought.
The last post introduced the levels of maturity, which are:
- Ad Hoc
- Common Goals
- Pilot
- Extend
- Standardize
- Optimize
Those levels are a pretty straightforward way of describing the maturation process of just about anything. So what’s really import is the other dimension which defines exactly what we’re maturing.
In the case of this model, we’re discussing SOA adoption maturity. SOA adoption is not simply about purchasing technology. No one can sell you an SOA, although there was someone selling “SOA in a box” back around Christmas on eBay in Australia. SOA adoption does involve new technologies that can provide support in service development and hosting, such as orchestration engines or web service frameworks, service connectivity, such as SOA appliances or ESBs, and service management. SOA adoption also involves organizational changes. If your organization is structured around application development, which team is responsible for building a service that spans multiple groups? SOA adoption involves governance, whether it be funding models, design time policies, or run time policies. SOA adoption involves new processes designed around the consumer/provider interaction. SOA adoption involves training and communication. How do we market services that have been created to ensure their reuse? Clearly, SOA adoption involves architecture. Enterprise architecture must provide appropriate reference architectures and reviews to ensure both tactical and strategic success. SOA adoption involves Operational Management. Services can’t be dumped into production and forgotten, we must take a proactive approach to monitoring and metric collection and feed that information back into the machine for continuous improvement.
SOA is not easy. If it were, we’d all be done by now. Every company will have different drivers, and different technology needs. An assessment of their maturity in SOA adoption should examine all of dimensions required.
SOA Maturity Model
David Linthicum recently re-posted his view on SOA maturity levels and I wanted to offer up an alternative view, as I’ve recently been digging into this subject for MomentumSI.
Interestingly, Dave calls out a common pattern that other models he’s seen define their levels around components and not degrees of maturity. He states:
While components are important, a maturity model is much more important, considering that products will change over time…
I completely agree on this. Maturity is not about what technologies you use, it’s about using them in the right way. Comparing this to our own maturity, just because you’re old enough to drive a car, doesn’t mean you’re mature. Just because you’ve purchased an ESB, built a web service, or deployed a registry doesn’t mean you’re mature.
Dave then presents his levels. I’ve cut and paste the first sentence that describes each level here.
- Level 0 SOAs are SOAs that simply send SOAP messages from system to system.
- Level 1 SOAs are SOAs that also leverage everything in Level 0 but add the notion of a messaging/queuing system.
- Level 2 SOAs are SOAs that leverage everything in Level 1, and add the element of transformation and routing.
- Level 3 SOAs are SOAs that leverage everything in Level 2, adding a common directory service.
- Level 4 SOAs are SOAs that leverage everything in Level 3, adding the notion of brokering and managing true services.
- Level 5 SOAs are SOAs that leverage everything in Level 4, adding the notion of orchestration.
While these levels may be an accurate portrayal of how many organizations leverage technology over time, I don’t see how they are an indicator of maturity, because there’s nothing that deals with the ability of the organization to leverage these things properly. Furthermore, not all organizations may proceed through these levels in the order presented by Dave. The easiest one to call out is level 5: orchestration. Many organizations that are trying to automate processes are leveraging orchestration engines. They may not have a common directory yet, they may have no need for content based routing, and they may not have a service management platform. You could certainly argue that they should have these things in place before leveraging orchestration, but the fact is, there are many paths that lead to technology adoption, and you can’t point to any particular path and say that is the only “right” way.
The first difference between my efforts on the MomentumSI model and Dave’s levels is that my view is targeted around SOA adoption. Dave’s model is a SOA Maturity Model, and there is a difference between that and a SOA Adoption Maturity Model. That being said, I think SOA adoption is the right area to be assessing maturity. To get some ideas, I first looked to other areas, such as CMMI and COBIT. If we look at just the names of the CMMI and COBIT levels, we have the following:
| Level | CMMI | COBIT |
| 0 | Non-Existent | |
| 1 | Initial | Initial |
| 2 | Managed | Repeatable |
| 3 | Defined | Defined |
| 4 | Quantitatively Managed | Managed |
| 5 | Optimizing | Optimized |
So how does this apply to SOA adoption? Quite well, actually. COBIT defines a level 0, and labels it as “non-existent.” When applied to SOA adoption, what we’re saying is that there is no enterprise commitment to SOA. There may be projects out there building services, but the entire effort is ad hoc. At level 1, both CMMI and COBIT label it as “Initial.” Again, applied to SOA adoption this means that the organization is in the planning stage. They are learning what SOA is and establishing goals for the enterprise. Simply put, they need to document an answer to the question “Why SOA?” At level 2, CMMI uses “Managed” and COBIT uses “Repeatable.” At this level, I’m going to side with CMMI. Once goals have been established, you need to start the journey. The focus here is on your pilot efforts. Pilots have tight controls to ensure their success. Level 3 is labeled as “Defined” by both CMMI and COBIT. When viewed from an SOA adoption effort, it means that the processes associated with SOA, whether it be the interactions required, or choosing which technologies to use where, have been documented and the effort is now underway to extend this to a broader audience. Level 4 is labeled as “Quantitatively Managed” by CMMI and “Managed” by COBIT. If you dig into the description on both of these, what you’ll find is that Level 4 is where the desired behavior is innate. You don’t need to handhold everyone to get things to come out the way you like. Standards and processes have been put in place, and people adhere to them. Level 5, as labeled by CMMI and COBIT is all about optimization. The truly mature organizations don’t set the processes, put them in place, and then go on to something else. They recognize that things change over time, and are constantly monitoring, managing, and improving. So, in summary, the maturity levels I see for SOA Adoption are:
- Ad hoc: People are doing whatever they want, no enterprise commitment.
- Common goals: Commitment has been established, goals have been set.
- Pilot: Initial efforts are underway with tight controls to ensure success.
- Extend: Broaden the efforts to the enterprise. As the effort expands beyond the tightly controlled pilots, methodology and governance become even more critical.
- Standardize: Processes are innate, the organization can now be considered a service-oriented enterprise.
- Optimize: Continued improvement of all aspects of SOA.
You’ll note that there’s no mention of technologies anyway in there. That’s because technology is just one aspect of it. Other aspects include your organization, governance, operational management, communications, training, and enterprise architecture. SOA adoption is a multi-dimensional effort, and it’s important to recognize that from the beginning. I find that the maturity model is a great way of assessing where an organization is, as well as providing a framework for measuring continued growth. That being said, your ability to assess it is only as good as your model.
Integration, not convergence
I recently had the opportunity to discuss the positioning of SOA appliances and it caused me to revisit my convergence model, as shown here:
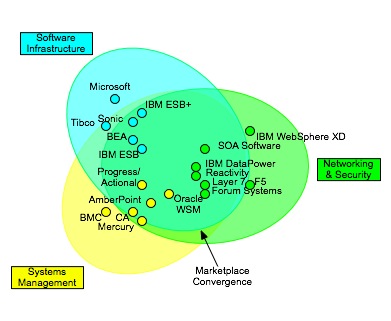
This diagram was intended to show the challenges that enterprise face in choosing vendors today, as there are solutions from multiple product spaces. The capabilities frequently associated with activities “in the middle” can come from network appliances, application servers, ESBs, service management systems, etc. My original post talked about the challenges that organizations face in trying to pick a solution. A key factor that must be weighed is the roles in the organization. My view is that the activities in the middle should beconfigured, not coded. That’s a topic for another post, however.
I started thinking about the future state, and realized that while the offerings from vendors overlap today, that shouldn’t be the long term trend. Even vendors that can cover the entire space do it with multiple products. The right model that we should be shooting for is one that looks like this:

In this model, we have four distinct components. Service hosting is concerned with the development and execution of services. Service connectivity consists of the capabilities in the middle: routing, mediation, etc. Service management provides management facilities over both of these domains. All of these systems rely on a set of information resources which provide both the information to process, as well as the policy and meta-information required for the appropriate execution of the systems. A registry/repository, therefore, would fall into the information resource domain.
What we’d like is for all of these domains to be integrated in an open, standards-based manner. Unfortunately, we’re still a ways off from that day. There have been some proprietary efforts to create integrated solutions that look like this, such as the Governance Interoperability Framework effort by Systinet, but there’s still a long way to go. None of the vendors associated with GIF are the big players in the service hosting space (IBM, BEA, Oracle, Microsoft, etc.), and the integration standards are not open. When we have open, integration standards, we can now begin to create the feedback loop.
One short-term issue that needs to improve is the tight coupling of management consoles to the platforms. In the model, service management is loosely coupled. It integrates with the other domains through loosely coupled services, all of the best practices of SOA. Today, service hosting platforms and service connectivity systems all come with their own management consoles. In order to enable this model, the management architecture of those systems must be built on SOA principles. That means that all of the capabilities that can be managed should be exposed as services. You want to deploy a new application to the application server? Call the application deployment service. This creates a great situation for automated build systems. Out of the box, the build process could be executed in your favorite BPEL engine, with controls for compilation, automated testing, source code tagging, and deployment all orchestrated through web service interactions. Now add in a feedback loop by which metrics cause additional provisioning, or even where an uncaught exception results in a tag being placed on the source files associated with the stack trace to aid in debugging. It all begins with having the services available. Ask your vendors one simple question: are all the capabilities available through the management console also available as services?
An answer to slum control
Vilas posted a response to some of the postings (here and here) I made regarding the relationship of city planning to EA/SOA. He provides an example of a business sponsor that promotes a program that can add million dollars to the bottom line, but has an extremely short timeline, one that requires the existing architectural guidelines, principles, and processes to be short-circuited, or more likely, completely ignored. He compares this effort to a slum getting developed in a nice city.
I’m not going to argue that this situation doesn’t happen. It does. What I will argue, however, is that the fact that it allowed to be built can be a case of ineffective governance. The governance policies and processes have to be about encouraging the desired behavior. If the policies and processes aren’t consistent with the desired behavior, it’s a case of bad governance. In this example, this is likely a rapid growth opportunity. If the enterprise as a whole is in a cost cutting mode, I have a hard time believing that this rapid growth scenario would pass the governance checks and be viewed as a “solid business case.” If the corporate leaders have decided that the best direction for the company is to cut costs, odds are that a project such as this will never make it out of the governance process to begin with. If the company is focused on increasing revenue and growth, odds are it has taken more of a federated governance model, and allows individual business units to make decisions that are in their own best interest, sometime introducing redundant technology in order to meet the schedule demands of the growth cycles. If the enterprise architects in this model are instituting technical governance that constrains that growth, again, they’re acting in a way that is inconsistent with the goals of the organization, a case of bad governance. In either case, that mismatch will eventually cause problems for the organization. In the case of city, it may bring in crime, lower property values, and cause prosperous businesses and their revenues to move elsewhere. In the business world, it could cause a lack of focus on core capabilities, cost overruns, and fragmentation within. None of these risks were probably included in the business plan.
This is the dilemma of the enterprise architect or really anyone with some authority in the governance process. Growth is usually something that is important and achievable in the short term, but difficult to sustain in the long term. Growth has to occur in other areas, while cost cutting measures must be introduced in the former areas. Cost cutting leading to the elimination of redundancy, and if the technology wasn’t planned for that eventual occurrence from the beginning, the effort to reduce costs may eat away any potential savings. This is where the service abstraction is extremely important. Correctly placed services can position a company to consolidate where appropriate down the road. It will pay benefits when a merger and acquisition must occur by providing an analysis point (the service portfolio) from both a business and technology perspective to better estimate the cost of the integration activities.
Upcoming Webinar on SOA Pilots
Alex Rosen and I will be giving a webinar next Friday on the role of pilots in achieving SOA success. I haven’t blogged on SOA Pilots in quite some time (March 23rd of last year, to be exact). It’s always interesting to go back and read some of my past posts to see how my thinking has evolved. I had quoted the ZapThink guys, as well as Miko Matsumura in that entry, stating:
Miko stated that the only ones getting it right were ZapThink, who state that “the things you do in a pilot are the exact opposite of what you need to do to get to enterprise scale.” For the record, I agree. This all comes down to defining the pilot properly. In their book, “Service Orient or Be Doomed!” Jason and Ron call out three SOA Pilot essentials: an architectural plan (the pilot will cover some portion of it), a specific scope, and clear acceptance criteria.
There shouldn’t be much controversy over these, but yet, the case studies and whitepapers that I see presented don’t have these elements, and it’s usually because the study is equating web services usage with SOA. Taking a user-facing customer portal and extending it by allowing customers to integrate their systems directly can be a good thing, but is it really an SOA pilot?
I went on in the entry to lock in on the subject of culture change, stating: “a proper SOA pilot is to pick a problem that will require the organization to see the cultural changes that are necessary to become a service provider.” I still think that this is the case, however, I would also say that I was being just as narrow as the teams that strictly focus on using Web Services for the first time.
What you’ll find in the webinar is that SOA adoption involves many dimensions. One of those dimensions is technology based. Another dimension is cultural. I’ve been working with my colleagues on a maturity model that outlines these dimensions and the stages that an organization goes through across all of them. Pilot efforts should cover all of these. It may be done in one large program, or there may be several pilot projects. Every organization is different, therefore, there is not a one size fits all project that every organization should embrace.
If this sounds interesting to you, then I encourage you to sign up here, and listen in on Friday the 16th, at 1pm Eastern Time (Noon central, 10AM Pacific).
