Archive for the ‘ITIL’ Category
 Clouds, Services, and the Path of Least Resistance
Clouds, Services, and the Path of Least Resistance
I saw a tweet today, and while I don’t remember it exactly, it went something like this: “You must be successful with SOA to be successful with the cloud.” My first thought was to write up a blog about the differences between infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS) and how they each relate to SOA until I realized that I wrote exactly that article a while ago as part of my “Ask the Expert” column on SearchSOA.com. I encourage you to read that article, but I quickly thought of another angle on this that I wanted to present here.
What’s the first vendor that comes to mind when you hear the words “cloud computing”? I’m sure someone’s done a survey, but since I don’t work for a research and analysis firm, I can only give you my opinion. For me, it’s Amazon. For the most part, Amazon is an infrastructure as a service provider. So does your success in using Amazon for IaaS have anything to do with your success with SOA? Probably not, however, Amazon’s success at being an IaaS provider has everything to do with SOA.
I’ve blogged previously about the relationship between ITIL/ITSM and SOA, but they still come from very different backgrounds, ITIL/ITSM being from an IT Operations point of view, and SOA being from an application development point of view. Ask an ITIL practitioner about services and you’re likely to hear “service desk” and “tickets” but not so likely to hear “API” or “interface” (although the DevOps movement is certainly changing this). Ask a developer about services and you’re likely to hear “API,” “interface,” or “REST” and probably very unlikely to hear “service desk” or “tickets”. So, why then does Amazon’s IaaS offering, something that clearly aligns better with IT operations, have everything to do with SOA?
To use Amazon’s services, you don’t call the service desk and get a ticket filed. Instead, you invoke a service via an API. That’s SOA thinking. This was brought to light in the infamous rant by Steve Yegge. While there’s a lot in that rant, one nugget of information he shared about his time at Amazon was that Jeff Bezos issued a mandate declaring that all teams will henceforth expose their data and functionality through service interfaces. Sometimes it takes a mandate to make this type of thinking happen, but it’s hard to argue with the results. While some people will still say there’s a long way to go in supporting “enterprise” customers, how can anyone not call what they’ve done a success?
So, getting back to your organization and your success, if there’s one message I would hope you take away from this, it is to remove the barriers. There are reasons that service desks and ticketing systems exist, but the number one factor has to be about serving your customers. If those systems make it inefficient for your customers, they need to get fixed. In my book on SOA Governance, I stated that the best way to be successful is to make the desired path the path of least resistance. There is very little resistance to using the Amazon APIs. Can the same be said of your own services? Sometime we create barriers by the actions we fail to take. By not exposing functionality as a service because your application could just do it all internally, in-process, we create a barrier. Then, when someone else needs it, the path of least resistance winds up being to replicate data, write their own implementation, or anything other than what we’d really like to see. Do you need to be successful with SOA to be successful with the cloud? Not necessarily, but if your organization embraces services-thinking, I think you’ll be positioning for greater success than without it.
Maintaining a Service Mentailty
On Twitter, Brenda Michelson of Elemental Links started a conversation with the question:
Do #entarch frameworks enable or constrain practice of (value from) enterprise architecture?
In my comments back to Brenda, it became clear to me that there’s a trap that many teams fall into, not just Enterprise Architecture, and that’s falling into an inward view, rather than an outward view.
As an example, I worked with a team once that was responsible for the creation, delivery, and evolution of data access services. Over time, teams that needed these services were expressing frustration that the services available were not meeting their needs. They could eventually get what they needed, but in a less than efficient manner. The problem was that the data services team primary goal was to minimize the number of services they created and managed. In other words, they wanted to make their job as easy as possible. In doing so, they made the job of their customers more and more difficult. This team had an inward view. It’s very easy to fall into this trap, as performance objectives frequently come from internally measured items, not from the view of the customer.
EA teams that obsess over the adoption of EA frameworks fall into the same category. Can EA frameworks be a valuable tool? Absolutely. But if your primary objective becomes proper adoption of the framework versus delivering value to your customers, you have now fallen into an internal view of your world, which is a recipe for failure.
Instead, teams should strive to maintain a service mentality. The primary focus should always be on delivering value to your customers. There’s a huge emphasis on EA becoming more relevant to the business, in order to do so, we need to deliver things that fit into the context of the business and how they currently make decisions. If we walk in preaching that they need to change their entire decision making process to conform to a framework, you’ll be shown the door. You must understand that you are providing a service to the teams you work with and helping them get their job done better that they could without you. While a framework can help, that should never be your primary focus. Internal optimizations of your process should be a secondary focus. In short, focus on what you deliver first, how you deliver it second. If you deliver useless information efficiently, it doesn’t do anyone any good.
A Lesson in Service Management
In the Wired magazine article on the relationship between AT&T and Apple (see: Bad Connection: Inside the iPhone Network Meltdown), the author, Fred Vogelstein, presents a classic service management problem.
In the early days of the iPhone, when data usage was coming in at levels 50% higher than what AT&T projected, AT&T Senior VP Kris Renne came to Apple and asked if they could help throttle back the traffic. Apple consistently responded that they were not going to mess up the consumer experience to make the AT&T network tenable.
In this conversation, AT&T fell into the trap that many service providers do: focusing on their internal needs rather than that of the customer. Their service was failing, and the first response was to try to change the behavior of their consumers to match what their service was providing, not to change the service to what the consumer needs.
I’ve seen this happen in the enterprise. A team whose role was to deliver shared services became more focused on minimizing the number of services provided (which admittedly made their job easier) than on providing what the customers needed. As a result, frustration ensued, consumers were unhappy and were increasingly unwilling to use the services. While not the case in this situation, an even worse possibility is where that service provider is the only choice for the consumer. They become resigned to poor service, and the morale goes down.
It is very easy to fall into this trap. A move to shared services is typically driven by a desire to reduce costs, and the fewer services a team has to manage, the lower their costs can be. This cannot be done at the expense of the consumer though. First and foremost, your consumers must be happy, and consumer satisfaction must be part of the evaluation process of shared service teams. Balance that appropriately with financial goals, and you’ll be in a better position for success.
Governance Technology and Portfolio Management
All content written by and copyrighted by Todd Biske. If you are reading this on a site other than my “Outside the Box” blog, it’s probably being republished without my permission. Please consider reading it at the source.
David Linthicum continued the conversation around design-time governance in cloud computing over at his InfoWorld blog. In it, he quoted my previous post, even though he chose to continue to use the design-time moniker. At least he quoted the paragraph where I state that I don’t like that term. He went on to state that I was “arguing for the notion of policy design,” which was certainly part of what I had to say, but definitely not the whole message. Finally, Dave made this statement:
The core issue that I have is with the real value of the technology, which just does not seem to be there. The fact is, you don’t need design-time service governance technology to define and define service policies.
Let’s first discuss the policy design comment. Dave is correct that I’m an advocate for policy-based service interactions. A service contract should be a collection of policies, most if not all of which will be focused on run-time interactions and can be enforced by run-time infrastructure. Taking a step backward, though, policy design is really a misnomer. I don’t think anyone really “designs” policies, they define them. Furthermore, the bulk of the definition that is required is probably just tweaking of the parameters in a template.
Now, moving to Dave’s second comment, he made it very clear that he was talking about governance technology, not the actual governance processes. Speaking from a technology perspective, I’ll agree that for policy management, which includes policy definition, all of the work is done through the management console of the run-time enforcement infrastructure. There are challenges with separation of concerns, since many tools are designed with a single administration team in mind (e.g. can your security people adjust security policies across services while your operations staff adjust resources consumption while your development team handles versioning, all without having the ability to step on each other’s toes or do things they’re not allowed to do?). Despite this, however, the tooling is very adequate for the vast majority (certainly better than 80-90% in my opinion) of enterprise use cases.
The final comment from me on this subject, however, gets back to my original post. Your SOA governance effort involves more than policy management and run-time interactions. Outside of run-time, the governance efforts has the closest ties to portfolio management efforts. How are you making your decisions on what to build and what to buy, whether provided as SaaS or in house? Certainly there is still a play for technology that support these efforts. The challenge, however, is that processes that support portfolio management activities vary widely from organization, so beyond a repository with a 80% complete schema for the service domain, there’s a lot of risk in trying to create tools to support it and be successful. How many companies actually practice systemic portfolio management versus “fire-drill” portfolio management, where a “portfolio” is produced on a once-a-year (or some other interval) basis in response to some event, and then ignored for the rest of the time, only to be rebuilt when the next drill occurs. Until these processes are more systemic, governance tools are going to continue to be add-ons to other more mature suites. SOA technologies tried to tie things to the run-time world. EA tools, on the other hand, are certainly moving beyond EA, and into the world of “ERP for IT” for lack of a better term. These tools won’t take over all corporate IT departments in the next 5 years, but I do think we’ll see increased utilization as IT continues its trend toward being a strategic advisor and manager of IT assets, and away from being the “sole provider.”
EA Service Management – Reporting
This is another blog on the subject of a service-based view of Enterprise Architecture. Previous posts focused on the actual service definitions (here and here) and a general view on communications, this one focuses on the actual management of those services, specifically on the notion of reporting.
In my experience, as teams try to transition to a service-based view, a key challenge is in moving from an inwardly-focused view to an outwardly-focused view. In other words, shifting to a focus on the customer. An easy way to encourage this shift is to think about your communication to the customer. If you think of examples of great service, it goes beyond the communication associated with service execution. As a simple example, think about your credit card. There are credit cards that simply allow you to make your purchases and then send you a bill. Some cards, however, send you a report every year that gives you information on how you’ve used your credit allowing you to make better financial plans. So, how can we take this same approach to the EA (or any other) service offerings?
The simple part of this is to make a commitment to communication with your customers. At a minimum, think about reporting to your direct customers and their management. In all likelihood, you’ll need to add two additional audiences to this. First, is senior management over EA. Depending on where EA sits in the organization, this could be senior IT leadership or it could be senior enterprise leadership. Second, is the group most people are used to dealing with, and that’s internal management of EA. The more complicated part of this is figuring out what to report and how frequently to report it. I hope to cover this in more detail in a future post, but for now, think about how you can add additional value to the relationship. Rather than simply reporting status of engagements, provide additional value through an analysis of activities, added information from EA research services, or some transparency into the activities occurring within Enterprise Architecture.
EA Communications
This seems to be the topic of the week with excellent posts on the subject from both Leo de Sousa and Serge Thorn. This has been on my to-do list since a meeting with Bruce Robertson where we discussed both my thinking on EA Services and Gartner’s, which also resulted in a blog post from Bruce. In that conversation, Bruce convinced me that communication should be a top level EA service, rather than an implied activity within all other EA services, as was my previous stance. This was also challenged by Aleks Buterman in our discussions on Twitter.
Bruce’s stance was that communications was essential to everything that EA does. If your EA team can’t communicate effectively, then their chances of success are greatly diminished. By defining it as a top level EA service, it emphasizes its importance for not just the EA team, but everyone who utilizes the EA services.
Given that assumption, what does the communication service look like? I think Leo gave a great start at a communication plan. In reality, the EA communication service shouldn’t be very different than any other communication service, the only difference is the subject being communicated. Therefore, let’s learn from practices of the communications experts. Leo relied on a communication plan created by a colleague that is used for many things, not just enterprise architecture. I’m trying a simliar approach, initially based on a template from ganthead.com, but has now been customized quite a bit. In the plan we capture a number of items. You’ll see there are many similarities to what Leo had to say, plus some additional items I think are important. The plan is a simple Excel spreadsheet, with each row representing a unique “audience.” These audiences do not have to be a mutually exclusive, in fact, it’s quite common to have one row targeted at a broad audience, and then other rows targeted at more narrow subgroups. For each audience, the following things are captured:
- Questions to answer / Information to present: In a nutshell, what are we trying to communicate to the audience? What are the two or three key items to present?
- Sensitivies: This one isn’t on Leo’s, but I think it’s very important. What are the biases and background that the audience has that may positively or negatively impact the effectiveness of the communication? For example, if your organization has tried the same initiative 5 different times, and you’re proposing the sixth, you should know that you’re walking into a room full of doubters.
- Mechanism: How will the communication be delived? This can involve multiple mechanisms including presentations, podcasts, webinars, blogs, whitepapers, etc.
- Objective: What is the objective of the communication for the audience? This is different than the information to present, this instead is the expected behavior you expect to see if the communication is successful. Obviously, the communication alone may not achieve the objective, but it should represent a big step in that direction.
- Author(s): Who will create the communications collateral?
- Presenter(s): Who will present the information?
- Delivery date(s): When will the communication be delivered, and if it’s an on-going process, at what frequency? If there are mutliple delivery dates, when will the last delivery occur?
- Evaluation Method: How will we evaluate the effectiveness of the communication? There may be multiple evaluations.
- Follow-up date: When will follow-up occur with the audience to gauge effectiveness and retention?
This may seem like a lot of formality, but I’ve seen the benefits of it first hand, and the risks associated with ad hoc communication efforts. My experiences with ad hoc have been hit or miss, but when the time was taken to develop a formal plan, the efforts have always been successful. I hope this helps you in your efforts.
EA Services: Part Two
Jeff Schneider posted the following comment to my previous post, “What are your EA Services?”
Your services feel too ‘responsive’ – like someone has to pick up the phone and call you in order for EA to be valuable. Thoughts?
I was hoping someone would ask a question along these lines, because it’s something I’ve thought a lot about. Services, by their nature, should seem very ‘responsive.’ After all, there should always be a service consumer and a service provider. The consumer asks, the provider does. In the context of an enterprise architecture team, or any other team for that matter, you do have to ask the question, “If no one is asking me to do this, why am I doing it?” Is that stance too theoretical, though?
When I think about this, I think services in this context (ITIL/ITSM) follow the same pattern that can be used for web services. There are services that are explicitly invoked at the request of a consumer, and then there are services that are executed in response to some event. In the latter case, the team providing the service is the one monitoring for the event. If some other team was monitoring for it, and then told your team to do something, then we’re back to the request/response style with one team acting as consumer and the other acting as the provider.
Coming back to the EA services, I think an Enterprise Architecture team will typically have a mix of request/response-style and event-driven services. It’s probably also true that if the EA team is closer to project activity, you’ll see more request/response services done on behalf of project teams, such as the Architectural Assessment Services and the Architectural Consulting Services I mentioned. If your EA team is more involved with portfolio management and strategic planning, then it’s possible that you may have more event-driven services, although these could still be request/response. Strategic direction could be driven by senior management, with direction handed down on areas of research. That direction represents a service request from that strategic planning group to the EA team. In an event-driven scenario, the EA team would be watching industry trends, metrics, and other things and making their own call on areas for research. It’s a subtle difference.
Anyway, I do think Jeff has a valid point, and as part of defining the services, you should classify the triggers that cause the service to be invoked. This will clearly capture whether they are event-driven or request/response. If your list is entirely request/repsonse, that’s probably something to look into. That may be what’s needed today, but you should be practicing good service management and planning for some event-driven services in the future if your team continues to provide value in the organization.
Thanks to Jeff Adkins for the good discussion about this on Twitter.
What are your EA Services?
A week or so ago, I asked about defining on EA services on Twitter. My use of the term services here is in more of the ITIL/ITSM sense, not what typically comes to mind when discussing SOA, but I could have another blog post just dedicated to that subject. I’ve been working to define EA services at work, and it’s been a very interesting exercise, and I had hoped that other EA’s (or former EA’s) on Twitter would have something to contribute.
Something that is a bit surprising to me, is that many IT teams struggle to explain exactly what they do, especially those whose primary purpose isn’t project work. This doesn’t mean that the team isn’t needed, but it does put you at risk of having the team be defined by the individuals rather than by their responsibilities. Depending on who the individual is, you get a different set of capabilities, making it difficult to quantify and measure what the team, rather than the individual does. A conversation with my boss and another team member on a different subject brought up the term “define by example” and we all agreed that it’s usually a bad thing. Examples are very important in illustrating the concept, but they shouldn’t be the definition. The same thing goes for a team. Your team should not by defined by individuals on it, but rather the individuals on it should be providing the defined services.
Getting back to the subject, the initial list of EA services I came up with, and vetted by Aleks Buterman, Leo de Sousa, and Brenda Michelson are:
- Architectural Assessment Services: The operations in this service include anything that falls into the review/approve/comment category, whether required or requested. Ad hoc architectural questions probably go here, but those are one that I’m still sitting on the fence about.
- Architectural Consulting Services: The operations in this service include anything where a member of the EA team is allocated to a project as a member of that project team, typically as a project architect. The day-to-day activities of that person would now be managed by a project manager, at least to the extent of the allocation.
- Architectural Research Services: The operations in this service are those that fall into the research category, whether formal or informal. This would include vendor conversations, reading analyst reports, case study reviews, participation in consortiums, etc.
- Architectural Reference Services: The operations in this service are those that entail the creation of reference material used for prescriptive guidance of activities outside of the EA team, such as patterns, reference models, reference architectures, etc.
- Architectural Standards Services: Very similar to reference services, this service is about the creation of official standards. I’m still on the fence as to whether or not this should be collapsed into a single service with the reference services. Sometimes, standards are treated differently than other reference material, so I’m leaving it as its own service for now.
- Architectural Strategy Services: Finally, strategy services capture the role of architecture in strategy development, such as the development of to-be architectures. If there is a separate strategy development process at your organization, this one represents the role of enterprise architecture in that process.
Now, the most interesting part of this process has not been coming up with this list, but thinking about the metadata that should be included for each of these services. Thinking like a developer, what are the inputs and outputs of each? Who can request them? Are any internal services (e.g. always requested by the EA manager) only, and which ones are external services (e.g. requested by someone outside of EA)? What are the processes behind these services? Are these services always part of a certain parent process, or are they “operations” in multiple processes? How do we measure these services? You can see why this suddenly feels very much like ITIL/ITSM, but it also has parallels to how we should think about services in the SOA sense, too. Thinking in the long term, all of these services need to be managed. What percentage of work falls into each bucket? Today, there may be a stronger need to establish solid project architecture, leading to a higher percentage of time spent consulting. Next year, it may shift to strategy services or some other category. The year after that, the service definitions themselves may need to be adjusted to account for a shift toward more business architecture and less technology architecture. Adjusting to the winds of change is what service management is all about.
So, my question to my readers is, what are your EA services? I’m sure I’m not the only EA out there who’s had to think about this. Even if your EA organization hasn’t, the next time you fill out your time card, think about what “service bucket” your efforts fall into. Do my categories make sense for what you do each week or month? If not, what’s missing. If it’s unclear which bucket something should go in, how would you redefine them? A consistent set of EA service definitions can definitely help all of us.
Understanding Your Engagement Model
People who have worked with me know that I’m somewhat passionate about having a well-defined engagement model. More often than not, I think we’ve created challenges for ourselves due to poorly-defined engagement models. The engagement model normally consists of “Talk to Person A” or “Talk to Team B” which means that you’re going to get a different result every time. It also means that interaction is going to be different, because no one is going to come to Person A or Team B with the same set of information, so the engagement is likely to evolve over time. In some cases, this is fine. If you’re part of your engagement model is to provide mentoring in a particular domain, then you need to recognize that the structure of the engagement will likely be time-based rather than information-based, at least in terms of the cost. Think of it as the difference between a fixed-cost standard offering, and a variable cost (usually based on time) from a consulting firm. I frequently recommend that teams try to express their service offerings in this manner, especially when involved in the project estimation process. Define what services should be fixed cost and define what services are variable cost, and what that variance depends on. This should be part of the process for operationalizing a service, and someone should be reviewing the team’s effort to make sure they’ve thought about these concerns.
When thinking about your services in the ITSM sense, it’s good to create a well-defined interface, just as we do in the web service sense. Think about how other teams will interact with your services. In some cases, it may be an asynchronous interaction via artifacts. An EA team may produce reference models, patterns, etc. for other teams to use in their projects. These artifacts are designed in their own timeline, separate from any project, and projects can access them at will. Requests to update them based on new information go into a queue and are executed according to the priority of the EA manager. On the other hand, an architecture review is executed synchronously, with a project team making a request for a review, provided they have the required inputs (an architectural specification, in most cases), with the output being the recommendations of the reviewer, and possibly a formal approval to proceed forward (or not).
If you’re providing infrastructure services, such as new servers, or configuration of load balancers, etc., in addition to the project-based interactions, you must also think about what your services are at run-time. While most teams include troubleshooting services, sometimes the interface is lacking definition. In addition, run-time services need to go beyond troubleshooting. When the dashboard lights are all green, what services do you provide? Do you provide reports to the customers of your services? There’s a wealth of information to be learned by observing the behavior of the system when things are going well, and that information can lead to service improvements, whether yours or someone else’s. Think about this when you’re defining your service.
The Role of the Service Manager
Tony Baer joined the SOA Consortium on one of its working group conference calls this week to discuss his research on connections between ITIL and SOA. Both he and Beth Gold-Bernstein have blogged about the call, Beth focusing on the broader topic of SOA and ITIL, and Tony talking about the topic of service ownership, as these topics were the meat of the conversation between Beth, Tony, and myself.
I’ve spent the past few years thinking about all things SOA, and recently, I completed the ITIL v3 Foundations certification and have been doing a lot of work in the ITIL/ITSM space. When you move away from the technology-side of the discussion and actually talk about the people and process side of the discussion, you’ll find that there are significant similarities between ITIL/ITSM adoption and SOA adoption. Tony had a diagram in his presentation that illustrated this that Beth reproduced on her blog. Having looked at this from both the SOA world of the application developer and the ITIL/ITSM world of IT operations, there’s a lot that we can learn from ITIL in our SOA adoption efforts. Foremost, ITIL defines a role of Service Manager. Anyone who’s listened to my panel discussions and heard my answer to the question, “What’s the one piece of advice you have for companies adopting SOA?” you’ll know that I always answer, “Make sure all your services have owners.” I’ve decided I like the term “Service Manager” better than “Service Owner” at this point, but if you refer to past posts of mine, you can think of these two terms synonymously.
So what does a service manager do? Let’s handle the easy one. Clearly, service management begins with the initial release of the service. The service manager is accountable for defining this release and putting the project in motion to get it out the door. This involves working with the initial service consumer(s) to go over requirements, get the interface defined, build, test, deploy, etc. Clearly, there’s probably a project manager, developers, etc. helping in the effort, but in a RACI model, it’s the service manager who has accountability. The work doesn’t end there, however. Once the service is in production, the service manager must be receiving reports on the service utilization, availability, etc. and always making sure it meets the needs of the consumer(s). In other words, they must ensure that “service” is being provided.
They must also be defining the next release of the service. How does this happen? Well, part of it comes from analysis of current usage, part of it comes from external events, such as a merger, acquisition, or new regulations, and part of it comes from seeking out new customers. Some consumers may come along on their own with new requests. Reading between the lines, however, it is very unlikely that a service manager manages only one service. It is more likely that they manage multiple services within a common domain. Even if it is one service, it’s likely that the service has multiple operations. The service manager is the one responsible for the portfolio of services and their operations, and trying to find the right balance between meeting consumer needs and keeping a maintainable code base. If there’s redundancy, the service manager is the one accountable for managing it and getting rid of it where it makes sense. This doesn’t negate the need for enterprise service portfolio management, because sometimes the redundancy may be spread across multiple service managers.
So what’s the list? Here’s a start. Add other responsibilities via comments.
- Release Management (a.k.a. Service Lifecycle Management)
- Production Monitoring
- Customer (Consumer) Management
- Service Management
- Marketing
- Domain Research: Trends associated with the service domain
- Domain-Specific Service Portfolio Management
Think hard about this, as it’s a big shift from many IT organizations today. How many organizations have their roles strictly structured around project lifecycle activities, rather than service lifecycle activities? How many organizations perform these activities even at an application level? It’s a definition change to the culture of many organizations.
Most Read Posts for 2008
According to Google Analytics, here are the top read posts from my blog for 2008. This obviously doesn’t account for people who read exclusively through the RSS feed, but it’s interesting to know what posts people have stumbled upon via Google search, etc.
10. Governance Does Not Imply Command and Control. This was posted in August of 2008, and intended to change the negative opinion many people have about the term “governance.”
9. To ESB or not to ESB. This was posted in July of 2007, and gave a listing of five different types of ESBs that exist today and how they may (or may not) fit into your environment.
8. Getting Started with SOA Governance. This was posted in September of 2008, just before my book was released. It emphasizes a policy first approach, stressing education over enforcement.
7. Dish DVR Upgrade. This was posted in November of 2007 and had little to do with SOA. It tells the story of how Dish Network pushed out an upgrade to the software on their DVRs that wiped out all of my existing timers, and I missed recording some shows as a result. The lesson for IT: even if you think there’s no chance that a change will impact someone, you still should make them aware that a change is occurring.
6. Most popular posts to date. This is rather humorous. This post from July of 2007 was much like this one. A list of posts that Google Analytics had shown as most viewed since January of 2006. Maybe this one will show up next year. It at least means someone enjoys these summary posts.
5. Dilbert’s Guide to Governance. In this post from June of 2007, I offered some commentary on governance in the context of a Dilbert cartoon that was published around the same timeframe.
4. Service Taxonomy. Based upon an analysis of search keywords people use that result in them visiting my pages, I’m not surprised to see this one here. This was posted in December of 2006, and while it doesn’t provide a taxonomy, it provides two reasons for having taxonomies: determining service ownership and choosing the technical implementation platform. I don’t think you should have taxonomies just to have taxonomies. If the classification isn’t serving a purpose, it’s just clutter.
3. Horizontal and Vertical Thinking. This was posted in May of 2007 and is still one of my favorite posts. I think it really captures the change in thinking that is required for more strategic solutions, however, I also now realize that the challenge is in determining when horizontal thinking is needed and when it is not. It’s not an easy question and requires a broad understanding of the business to answer correctly.
2. SOA Governance Book. This was posted in September of 2008 and is when I announced that I had been working on a book. Originally, this had a link to the pre-order page from the publisher, later updated to include direct links there and to the page on Amazon. You can also get it from Amazon UK, Barnes and Noble, and other online bookstores.
1. ITIL and SOA. Seeing this post come in at number one was a surprise to me. I’m glad to see it up there, however, as it is something I’m currently involved with, and also an area in need of better information. There are so many parallels between these two efforts, and it’s important to eliminate the barriers between the developer/architecture world of SOA and the infrastructure/operations world of ITIL/ITSM. Look for more posts on this subject in 2009.
What are the Services?
I recently completed a certification in ITIL v3 Foundations. On the plus side, I found that the ITIL framework provided some great structure around the concept of service management that is very applicable to SOA. There was one key question, however, that I felt was left unanswered. What are the services?
My assumption going in was that ITIL was very much about running IT operations within an enterprise, so I expected to see some sort of a service domain model associated with the “business of IT.” That’s not the case, at least not in the material I was given. There are a number of roles defined that are clearly IT specific, but overall, I’d say that many of the processes and functions presented were not specific to IT at all. As an example, ITIL foundations won’t tell you whether server provisioning or application deployment should be services in your catalog or not. Without this, an effort to adopt ITIL can struggle in the same way as an SOA adoption effort can. I’ve seen first hand where an organization thrashed around what the right operational and engineering services were. ITIL does offer the right guidance in helping you define them, in that it begins with understanding your customer.
This is the same question where many SOA initiatives struggle. We can have lots of conceptual talk about how to build services the right way, but actually defining the services that should be built is a challenge. In both ITIL and SOA adoption, there is a penalty for defining too many services. It’s probably much more pronounced in ITIL, because those services likely have a higher cost since managing and using those services tends to have a higher cost in the manual effort than managing and using a web service, although, if you’re doing business-driven SOA, the costs may be very similar.
Overall, I definitely felt there is a lot of value in the ITIL v3 framework, and I think if you are leading an SOA adoption effort, it’s worth learning about, as it will help your efforts. If you’re looking to improve IT operations, it will likewise help your efforts. Just know that there you’ll still need to figure out what your services are on your own, and that can have a big impact on the success of your adoption efforts.
More on ITIL and SOA
In his “links” post, James McGovern was nice enough to call additional attention to my recent ITIL and SOA post, but as usual, James challenged me to add additional value. Here’s what he had to say:
Todd Biske provides insight into how ITIL can benefit SOA but misses an opportunity to provide even more value. While it is somewhat cliche to talk about continual process improvement, it would be highly valuable to outline what types of feedback do operations types observe that could benefit the software development side of the house.
I thought about this, and it actually came down to one word: measurement. You can’t improve what you’re not measuring. It’s debatable as to whether or not operations does any better than software development in measuring the service they provide, but operations is probably in a better position to do so. Why? There is less ambiguity about the service being provided. For example, a common service from operations in big IT shops is building servers. They can measure how many servers they’ve built, how quickly they’ve been built, and they and how correctly they’ve been built, among other things.
In the case of softwre development, is the service being provided software development, or is the capability provided by the software? I’d argue that most shops are focused on the former. If you measure the “software development” service, you’ll probably measure whether the effort was completed on time and on budget. If, instead, you measure based on the capability provided by the software, it now becomes about the business value being provided by the software, which, in my opinion, is the more important factor. Taking this latter view also positions the organization for future modifications to the solutions. If my focus is solely on time and budget, why wouldn’t I disband the team when the project is done? The team has no vested interest in adding additional value. They may be challenged on some other project to improve their delivery time or budget accuracy, but there’s no connection to business value. Putting it very simply, what good does it do to deliver an application on time and on budget that no one uses?
So, back to the question, what can we learn from the ops side of the world. If ops has drunk the ITIL kool-aid, then they should be measuring their service performance, the goals for it should be reflected in the individual goals of the operations team, and it should be something that allows for improvement over time. If the measurement falls into the “one-time” measurement category, like delivering on-time and on-budget, that should be a dead giveaway that you may be measuring the wrong thing, or not taking a service-based view on your efforts.
ITIL and SOA
I’ve been involved in some discussions recently around the topic of ITIL Service Management. While I’m no ITIL expert, the little bit of information that I’ve gleaned from these discussions has shown me that there are strong parallels between SOA and ITIL Service Management.
There’s the obvious connection that both ITIL Service Management and SOA contain the term “service,” but it goes much deeper than that (otherwise, this wouldn’t be worth posting). There are five major domains associated with ITIL: service strategy, service design, service transition, service operation, and continual service improvement. Here’s a picture that I’ve drawn that tries to represent them:

Keeping it very simple, service strategy is all about defining the services. In fact, there’s even a process within that domain called “Service Portfolio Management.” Service Design, Service Transition, and Service Operation are analogous to the tradition software development lifecycle (SDLC): service design is where the service gets defined, service transition is where the service is implemented, and service operation is where the service gets used. Continual Service Improvement is about watching all aspects of each of these domains and striving to improve it.
Now back to SOA side of the equation. I’ve previously posted on the change to the development process that is possible with SOA, most recently, this one. The essence of it is that SOA can shift the thinking from a traditional linear lifecycle that ends when a project goes live to a circular lifecycle that begins with identification of the service and ends with the decommissioning of the service. Instead, the lifecycle looks like this:
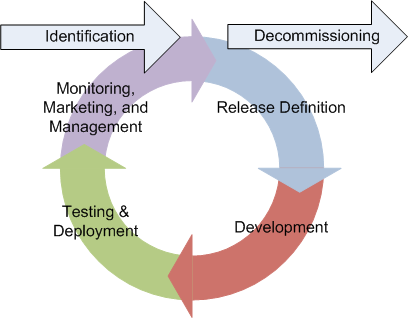
The steps of release definition, development, testing, and deployment are the normal SDLC activities, but added to this is what I call the triple-M activity: monitoring, marketing, and management. We need to do the normal “keep the lights on” activities associated with monitoring, but we also need to market the service and ensure its continued use over time, as well as manage its current use and ensure that it is delivering the intended business value. If improvements can be made through either improvements in delivery or by delivering additional functionality, the cycle begins again. This is analogous to the ITIL Service Management Continual Service Improvement processes. While not shown, clearly there is some strategic process that guides the identification and decommissioning activities associated with services, such as application portfolio management. Given this, these two processes have striking similarities.
What’s the point?
The message that I want you to take away is that we should be thinking about application and “web” service delivery in the same way that we are thinking about ITIL service delivery. Many people think ITIL is only about IT operations and the infrastructure, but that’s not the case. If you’re a developer, it equally applies to the applications that you are building and delivering. Think of them in terms of services and the business value that they deliver. When the project for version 1 ends, don’t stop thinking about it. Put in place appropriate metrics and reporting to ensure that it is delivering the intended value and watch it on a regular basis. Understand who your “users” are (it could be other systems and the people repsonsible for them), make sure they’re happy, and seek out new ones. Adopt a culture of continuous improvement, rather than simply focus on meeting the schedule and the budget and then waiting for the next project assignment.
