Archive for the ‘IT’ Category
 Models of EA
Models of EA
One thing that I’ve noticed recently is that there is no standard approach to Enterprise Architecture. Some organizations may have Enterprise Architecture on the organizational chart, other organizations may merely have an architectural committee. One architecture team may be all about strategic planning, while another is all about project architecture. Some EA teams may strictly be an approval body. I think the lack of a consistent approach is an indicator of the relative immaturity of the discipline. While groups like Shared Insights have been putting on Enterprise Architecture conferences for 10 years now, there are still many enterprises that don’t even have an EA team.
So what is the right approach to Enterprise Architecture? As always, there is no one model. The formation of an EA team is often associated with some pain point in the enterprise. In some organizations, there may be a skills gap necessitating the formation of an architecture group that can fan out across multiple projects, providing project guidance. A very common pain point is “technology spaghetti.â€? That is, over time the organization has acquired or developed so many technology solutions that the organization may have significant redundancy and complexity. This pain point can typically result in one of two approaches. The first is an architecture review board. The purpose of the board is to ensure that new solutions don’t make the situation any worse, and if possible, they make it better. The second approach is the formation of an Enterprise Architecture group. The former doesn’t appear on the organization chart. The latter does, meaning it needs day to day responsibilities, rather than just meeting when an approval decision is needed. Those day to day activities can be the formation of reference architectures and guiding principles, or they could be project architecture activities like the first scenario discussed. Even in these scenarios, however, Enterprise Architecture still doesn’t have the teeth it needs. Reference architectures and/or guiding principles may have been created, but these end state views will only be reached if a path is created to get there. This is where strategic planning comes into play. If the EA team isn’t involved in the strategic planning process, then they are at the mercy of the project portfolio in achieving the architectural goals. It’s like being the coach or manager of a professional sports team but having no say whatsoever in the player personnel decisions. The coach will do the best they can, but if they were handed players who are incompatible in the clubhouse or missing key skills necessary to reach the playoffs, they won’t get there.
You may be thinking, “Why would anyone ever want an EA committee over a team?â€? Obviously, organizational size can play a factor. If you’re going to form a team, there needs to enough work to sustain that team. If there isn’t, then EA becomes a responsibility of key individuals that they perform along with their other activities. Another scenario where a committee may make sense is where the enterprise technology is largely based on one vendor, such as SAP. In this case, the reference architecture is likely to be rooted in the vendor’s reference architecture. This results in a reduction of work for Enterprise Architecture, which again, has the potential to point to a responsibility model rather than a job classification.
All in all, regardless of what model you choose for your organization, I think an important thing to keep in mind is balance. An EA organization that is completely focused on reference architecture and strategic planning runs the risk of becoming an ivory tower. They will become disconnected from the projects that actually make the architecture a reality. The organization runs a risk that a rift will form between the “practitionersâ€? and the “strategists.â€? Even if the strategists have a big hammer for enforcing policy, that still doesn’t fix the cultural problems which can lead to job dissatisfaction and staff turnover. On the flip slide, if the EA organization is completely tactical in nature, the communication that must occur between the architects to ensure consistency will be at risk. Furthermore, there will still be no strategic plan for the architecture, so decisions will likely be made according to short term needs dominated by individual projects. The right approach, in my opinion, is to maintain a balance of strategic thinking and tactical execution within your approach to architecture. If the “officialâ€? EA organization is focused on strategic planning and reference architecture, they must come up with an engagement model that allows bi-directional communication with the tactical solution architects to occur often. If the EA team is primarily tasked with tactical solution architecture, then they must establish an engagement model with the IT governance managers to ensure that they have a presence at the strategic planning table.
How many versions?
While heading back to the airport from a recent engagement, Alex Rosen and I had a brief discussion on service versioning. He said, “you should blog on that.” So, thanks for idea Alex.
Sooner or later, as you build up your service library, you’re going to have to make a change to the service. Agility is one of the frequently touted benefits of SOA, and one way of looking at it is the ability to respond to change. When this situation arises, you will need to deal with versioning. In order to remain agile, you should prepare for this situation in advance.
There are two extreme viewpoints on versioning, and not surprisingly, they match up with the two endpoints associated with a service interchange- the service consumer and the service provider. From the consumers point of view, the extreme stance would be that the number of versions of a service remain uncapped. In this way, systems that are working fine today don’t need to be touched if a change is made that they don’t care about. This is great for the consumer, but it can become a nightmare for the provider. The number of independent implementations of the service that must be managed by the provider is continually growing, increasing the management costs thereby reducing the potential gains that SOA was intended to achieve. In a worst-case scenario, each consumer would have their own version of the service, resulting in the same monolithic architectures we have today, except with some XML thrown in.
From the providers point of view, the extreme stance would be that only one service implementation ever exists in production. While this minimizes the management cost, it also requires that all consumers move in lock step with the service, which is very unlikely to happen when there are more than one consumer involved.
In both of these extreme examples, I’m deliberately not getting into the discussion of what the change is. While backwards compatibility can have influence on this, regardless of whether the service provider claims 100% backwards compatibility or not, my experiences have shown that both the consumer and the provider should be executing regression tests. My father was an electrician, and I worked with him for a summer after my freshman year in college. He showed me how to use a “wiggy” (a portable voltage tester) for checking whether power was running to an outlet, and told me “If you’re going to work an outlet, always check if it’s hot. Even if one of the other electricians or even me tells you the power is off, you still check if it’s hot.” Simply put, you don’t want to get burned. Therefore, there will always be a burden on the service consumers when the service changes. The provider should provide as much information as possible so that the effort of the consumer is minimized, but the consumer should never implicitly trust that what the provider says is accurate without testing.
Back to the discussion- if we have these two extremes, the right answer is somewhere in the middle. Choosing an arbitrary number isn’t necessarily a good approach. For example, suppose the service provider states that no more than 3 versions of a service will be maintained in a production. Based upon high demand, if that service changes every 3 months, that means that the version released in January will be decommissioned in September. If the consumer of that first version is only touched every 12 months, you’ve got a problem. You’re now burdening that consumer team with additional work that did not fit into their normal release cycle.
In order to come up with a number that works, you need to look at both the release cycle of the consuming systems as well as the release cycle of the providers and find a number that allows consumers to migrate to new versions as part of their normal development efforts. If you read that carefully, however, you’ll see the assumption. This approach assumes that a “normal release cycle” actually exists. Many enterprises I’ve seen don’t have this. Systems may be released and not touched for years. Unfortunately, there’s no good answer for this one. This may be a symptom of an organization that is still maturing in their development processes, continually putting out fires and addressing pain points, rather than reaching a point of continuous improvement. This is representative of probably the most difficult part of SOA- the culture change. My advice for organizations in this situation is to begin to migrate to a culture of change. Rather than putting an arbitrary cap on the number of service versions, you should put a cap on how long a system can go without having a release. Even if it’s just a collection of minor enhancements and bug fixes, you should ensure that all systems get touched on a regular basis. When the culture knows that regular refreshes are part of the standard way of doing business, funding can be allocated off the top, rather than having to be continually justified against major initiatives that will always win out. It’s like our health- are you better off having regular preventative visits to your doctor in addition to the visits when something is clearly wrong? Clearly. Treat your IT systems the same way.
The value of events
Joe McKendrick quoted a previous blog entry of mine, but he prefaced my quotes with the statement that I was “questioning the value of EDA to many businesses.” One of things that any speaker/author has to always deal with is the chance that the message we hope comes out doesn’t, and I think this is one of those cases. That being said, if you feel like you are misrepresented, it probably means you didn’t explain it well in first place! So, in the event that others are feeling that I’m questioning the value of EDA, I thought I’d clarify my stance. I am a huge fan of events and EDA. Events can be very powerful, but just as there has been lots of discussions around the difference between SOA and ABOS- a bunch of services, the same holds true for EDA.
The problem does not lie with EDA. EDA, as a concept, has the potential to create value. EDA will fail to produce value, just as SOA will, if it is incorrectly leveraged. Everyone says SOA should begin with the business. Guess what, EDA should as well. While the previous entries I’ve posted and the great comments from the staff at Apama and their postings have called out some verticals where EDA is already being applied successfully, I’m still of the opinion that many businesses would be at significant risk of creating ABOE- a bunch of events. This isn’t a knock on the potential value of events, it’s a knock on the readiness of the business to realize that potential. If the business isn’t thinking of themselves in a service-oriented context, they are unlikely to reach the full potential of SOA. If the business isn’t thinking of themselves in an event-driven context, they are unlikely to reach the full potential of EDA.
Teaming Up for SOA
I recently “teamed up” with Phil Windley. He interviewed me for his latest InfoWorld article on SOA Governance which is now available online, and is in the March 5th print issue. Give it a read and let me know what you think. I think Phil did a great job in articulating a lot of the governance challenges that organizations run into. Of the areas where I was quoted, the one that I think is a significant culture change is the funding challenge. It’s not just about getting funding for shared services which is a challenge on its own. It’s also a challenge of changing the way that organizations make decisions to include architectural elements in the decision. Many organizations that I have dealt with all tend to be schedule driven. That is, the least flexible element of the project is schedule. Conversely, the thing that always gives is scope. Unfortunately, it’s not usually visible scope, it’s usually the difference in taking the quickest path (tactical) versus the best path (strategic). If you’re one of many organizations trying to do grass roots SOA, this type of IT governance makes life very difficult as the culture rewards schedule success, not architectural success. It’s a big culture shift. Does your Chief Architect have a seat at the IT Governance table?
Anyway, I hope you enjoy the article. Feel free to post your questions here, and I’d be happy to followup.
IT in homes, schools
I’ve had some lightweight posts on SOA for the home in the past, and for whatever reason, it seems to be tied to listening to IT Conversations. Well, it’s happened again. In Phil and Scott’s discussion with Jon Udell, they lamented the problems of computers in the home. Phil discussed the issues he’s encountered with replacing servers in his house and moving from 32-bit to 64-bit servers (nearly everything had to be rebuilt, he indicated that he would have been better off sticking with 32-bit servers). Jon and Phil both discussed some of the challenges that they’ve had in helping various relatives with technology.
It was a great conversation and made me think of a recent email exchange concerning my father-in-law’s school. He’s a grade school principal, and I built their web site for them several years ago. They host it themselves, and the computer teacher has done a great job in keeping it humming along. That being said, there’s still room for improvement. Many of the teachers still host their pages externally. My father-in-law sends a letter home with the kids each week that is a number of short paragraphs and items that have occurred throughout the week. Boy, that could easily be syndicated as a blog. Of course, that would require installing WordPress on the server, which while relatively easy for me, is something that could get quite frustrating for someone not used to operating at the command line. Anyway, the email conversation was about upgrading the server. One of the topics that came up was hosting email ourselves. Now, while it’s very easy to set up a mail server, the real concern here comes up with reliability. People aren’t going to be happy if they can’t get to their email. Even if we just look at the website, as it increasingly becomes part of the way the school communicates with the community, it starts to become critical.
When I was working in an enterprise, redundancy was the norm. We had load balancers and failover capabilities. How many people have a hardware load balancer at home? I don’t. You may have a linux box that does this, but it’s still a single point of failure. A search at Amazon really didn’t turn up too many options for the consumer, or even a cash-strapped school for that matter. This really brings up something that will become an increasing concern as we march toward a day where connectivity is ubiquitous. Vendors are talking about the home server, but when corporations have entire staffs dedicated to keeping those same technologies running, how on earth are we going to expect Mom and Pop in Smalltown U.S.A. to be able to handle the problems that will occur?
Think about this. Today, I would argue that most households still have normal phones and answering machines. Why don’t we have the email equivalent? Wouldn’t it be great if I could purchase a $100 device that I just into my network and now have my own email server? Yes, it would be okay if I had to call my Internet provider and say, “please associate this with biske.com” just as I must do when I establish a phone line. What do I do, however, if that device breaks? What if it gets hacked and becomes a zombie device contributing to the dearth of spam on the Internet? How about a device that enables me to share videos and pictures with friends and family? Again, while hosted solutions are nice, it would be far more convenient to merely pull them off the camcorder and digital camera and make it happen. I fully believe that the right thing is to always have a mix of options. Some people will be fine with hosted solutions. Some people will want the control and power of being able to do it themselves, and there’s a marketplace for both. I get tired of these articles that say things like “hosted productivity apps will end the dominance of Microsoft Office.” Phooey. It won’t. It will evolve to somewhere in the middle, rather than one side or the other. Conversations like that are always like a pendulum, and the pendulum always swings back. I’m off on a tangent, here. Back to the topic- we are going to need to make improvements in orders of magnitude on the management of systems today. Listen to the podcast, and here the things that Jon and Phil, two leading technologists that are certainly capable of solving most any problem, lament. Phil gives the example of calls from his wife (I get them as well) that “this thing is broken.” While he immediately understands that there must be a way to fix it, because we understand the way computers operate behind the scenes, the average joe does not. We’ve got a long way to go to get the ubiquity that we hope to achieve.
Metrics, metrics, metrics
James McGovern threw me a bone in a recent post, and I’m more than happy to take it. In his post, “Why Enterprise Architects need to noodle metrics…” he asks:
Hopefully bloggers such as Robert McIlree, Scott Mark, Todd Biske and others would be willing to share not only successes within their own enterprise when it comes to metrics but also any unintended consequences in terms of collecting them.
I’m a big, big fan of instrumentation. One of the projects that I’m most proud of was when we built a custom application dashboard using JMX infrastructure (when JMX was in its infancy) for a pretty large web-based system. The people that used it really enjoyed the insight it gave them into the run-time operations of the system. I personally didn’t get to use it, as I was rolled onto another project, but the operations staff loved it. Interesting, my first example of metrics being useful comes from that project, but not from the run time management. It came from our automated build system. At the time, we had an independent contractor who was acting as a project management / technical architecture mentor. He would routinely visit the web page for the build management system and record the number of changed files for each build. This was a metric that the system captured for us, but no one paid much attention to it. He started posting graphs showing the number of changed files over time, and how we had spikes before every planned iteration release. He let us know that those spikes disappeared, we weren’t going live. Regardless of the number of defects logged, the significant amount of change before a release was a red flag for risk. This message did two things: first, it kept people from working to a date, and got them to just focus on doing their work at an appropriate pace. Secondly, I do think it helped up release a more stable product. Fewer changes meant more time for integration testing within the iteration.
The second area where metrics have come into play was the initial use of Web Services. I had response time metrics on every single web service request in the system. This became valuable for many reasons. First, because the thing collecting the new metrics was new infrastructure, everyone wanted to blame it when something went wrong. The metrics it collected easily showed that it wasn’t the source of any problem, and actually was a great tool in narrowing where possible problems were. The frustration switched more to the systems that didn’t have these metrics available because they were big, black boxes. Secondly, we caught some rogue systems. A service that typically had 200,000 requests per day showed up on Monday with over 3 million. It turns out a debugging tool had been written by a project team, but that tool itself had a bug and started flooding the system with requests. Nothing broke, but had we not had these metrics and someone looking at them, it eventually would have caused problems. This could have went undetected for weeks. Third, we saw trends. I looked for anything that was out of the norm, regardless of whether any user complained or any failures occurred. When the response time for a service had doubled over the course of two weeks, I asked questions because that shouldn’t happen. This exposed a memory leak that was fixed. When loads that had been stable for months started going up consistently for two weeks, I asked questions. A new marketing effort had been announced, resulting in increased activity for one service consumer. This marketing activity would have eventually resulted in loads that could have caused problems a couple months down the road, but we detected it early. An unintended consequence was a service that showed a 95% failure rate, yet no one was complaining. It turns out a SOAP fault was being used for a non-exceptional situation at the request of the consumer. The consuming app handled it fine, but the data said otherwise. Again, no problems in the system, but it did expose incorrect use of SOAP.
While these metrics may not all be pertinent to the EA, you really only know by looking at them. I’d much rather have an environment where metrics are universally available and the individuals can tailor the reporting and views to information they find pertinent. Humans are good at drawing correlations and detecting anomalies, but you need the data to do so. The collection of these metrics did not have any impact on the overall performance of the system, however, they were architected to ensure that. Metric collection should be performed as an out-of-band operation. As far the practice of EA is concerned, one metric that I’ve seen recommended is watching policy adherence and exception requests. If your rate of exception requests is not going down, you’re probably sitting off in an ivory tower somewhere. Exceptions requests shouldn’t be at zero, either, however, because then no one is pushing the envelope. Strategic change shouldn’t solely come from EA as sometimes the people in the trenches have more visibility into niche areas for improvement. Policy adherence is also needed to determine what policies are important. If there are policies out there that never even come up in a solution review, are they even needed?
The biggest risk I see with extensive instrumentation is not resource consumption. Architecting an instrumentation solution is not terribly difficult. The real risk is in not provided good analytics and reporting capabilities. It’s great to have the data, but if someone has to perform extracts to Excel or write their own SQL and graphing utilities, they can waste a lot of time that should be spent on other things. While access to the raw data lets you do any kind of analysis that you’d like, it can be a time-consuming exercise. It only gets worse when you show it to someone else, and they ask whether you can add this or that.
EDA begins with events
Joe McKendrick asks, “Is EDA the ‘new’ SOA?” First, I’ll agree with Brenda Michelson that EDA is an architecture that can effectively work in conjunction with SOA. While others out there view EDA as part of SOA, I think a better way of viewing it would be that services and events must both be part of your technology architecture.
The point I really want to make however, which expounds on my previous post, is that I simply think event-oriented thinking is the exception, rather than the norm for most businesses. I’m not speaking about events in the technical sense, but rather, in the business sense. What businesses are truly event driven, requiring rapid response to change? Certainly, the airlines do, as evidenced by JetBlue’s recent difficulties. There are some financial trading sectors that must operate in real-time, as well. What about your average retail-focused company, however? Retail thinking seems to be all about service-based thinking. While you may do some cold calls, largely, sales happen when someone walks into the store, goes to the website, or calls on the phone. It’s a service-based approach. They ask, you sell. What are the events that should be monitored that would trigger a change in the business? For companies that are not inherently event-driven, the appropriate use of events are for collecting information and spotting trends. Online shopping can be far more informative for a company than brick-and-mortar shopping because you’ve got the clickstream trail. Even if I don’t buy something, the company knows what I entered in the search box, and what products I looked at. If I walk into Home Depot and don’t purchase anything, is there any record of why I came into the store that day?
Again, how do we begin to go down the direction of EDA? Let’s look at an event-driven system. The October 2006 issue of Business 2.0 had a feature on Steve Sanghi, CEO of Microchip Technology. The article describes how he turned around Microchip by focusing on commodity processors. As an example, the articles states that Intel’s automotive-chip division was pushing for “a single microprocessor near the engine block to control the vehicle’s subsystems and accessories.” Microchip’s approach was “to sprinkle simpler, cheaper, lower-power chips throughout the vehicle.” Guess what, today’s cars have about 30 micro-controllers.
So, what this says is that the appropriate event-based architecture is to have many, smaller points of control that can emit information about the overall system. This is the way that many systems management products work today- think SNMP. To be appropriate for the business, however, this approach needs to be generating events at the business level. Look at the applications in your enterprise’s portfolio and see how many of them actually publish any sort of data on how it is being used, even if it’s not in real time. We need to begin instrumenting our systems and exposing this information for other purposes. Most applications are like the checkout counter at Home Depot. If I buy something, it records it. If I don’t buy something and just exit the store, what valuable information has been missed that could improve things the next time I visit?
I’d love to see events become more mainstream, and I fully believe it will happen. I certainly won’t argue that event-driven systems can be more loosely coupled, however, I’ll also add that the events we’re talking about then are not necessarily the same thing as business events. Many of those things will never be exposed outside of IT, nor should they be. It’s the proper application of business events that will drive companies opening up their wallets to purchase new infrastructure built around that concept.
What’s the big deal about BPEL
Courtesy of this news release from InfoWorld, I found out that Microsoft Windows Workflow Foundation (WWF, which has nothing to do with endangered animals or professional wrestlers) is going to support BPEL. This is a good thing, but what does it really mean?
I’ll admit that I’ve never gotten very excited about BPEL. My view has always been that it’s really important as an import/export format. You should have a line item on your RFI/RFP that says, “supports import/export of BPEL.” You should ask the sales guy to demonstrate it during a hands-on section. Beyond this, however, what’s the big deal?
The BPM tools I’ve seen (I’ll admit that I haven’t seen them all nor even a majority of them) all have a nice graphical editor where you drag various shapes and connectors around, and they probably have some tree-like view where you draw lines between your input structure and your output structure. At best, you may need to hand code some XPath and some very basic expressions. The intent of this environment is to extract the “business process” from the actual business services where the heavy duty processing occurs. If you sort through the marketing hype, you’ll understand that this is all part of a drive to raise the level of abstraction and allow IT systems to be leveraged more efficiently. While we may not be there yet, the intent is to get tools into the hands of the people driving the requirements for IT- the business. Do you want your business users firing up XML Spy and spending their time writing BPEL? I certainly don’t.
What are the important factors that we should be concerned about with our BPM technologies, then? Repeating a common theme you’ve seen on this blog, it’s the M: Management. No one should need to see BPEL unless you’re migrating from one engine to another. There shouldn’t be a reason to exchange BPEL between partners, because it’s an execution language. Each partner executes their own processes, so the key concern is the services that allow them to integrate, not the behind the scenes execution. What is important is seeing the metrics associated with the execution of the processes to gain an understanding of the bottlenecks that can occur. You can have many, many moving parts in an orchestration. Your true business process (that’s why it was in quotes earlier) probably spans multiple automated processes (where BPEL applies), multiple services, multiple systems, and multiple human interactions. Ultimately, the process is judged by the experiences of the humans involved, and if they start complaining, how do you figure out where the problems are? How do you understand how other forces (e.g. market news, company initiatives, etc.) influence the performance of those processes. I’d much rather see all of the vendors announcing support for BPEL begin announcing support for some standard way of externalizing the metrics associated with process execution for a unified business process management view of what’s occurring, regardless of the platforms where everything is running, or how many firewalls need to be traversed.
The human side of SOA/BPM
Two recent posts that were completely unrelated have prompted me to write a little bit about the human interaction side of SOA and BPM. First, in response to the debate on maturity levels between myself and David Linthicum, Lori MacVittie posted this entry on the F5 DevCentral blogs. She didn’t get into the debate on maturity levels, but rather brought up a point about the use of the term orchestration. She states:
Orchestration of applications is a high level automation mechanism that can’t really be completed until there is a solid underlying SOA infrastructure and set of common services in place. It’s the pinnacle of SOA achievement, the ultimate proof that an organization SOA can indeed provide the benefits touted by pundits. But orchestration of services should also be the mechanism by which applications are constructed.
The second post that caught my eye was Ismael Ghalimi’s post, “What is Wrong with BPM.” In this post, he talks about the problems customers face in selecting a BPM product and some of the things that customers run into after the purchase has been made and they try leveraging the solution on one of their real business problems. He states:
Then comes the really fun part: the business folks want a different user interface for their workflow. The one you got out of the box seems to be working pretty well, and you could display your company logo at the top left, but somehow the suits have something different in mind, and they want it now. They paid $300,000 for some magic pixie dust that gives them business agility, and they expect it to make you a contortionist worthy of a full-time job with Cirque du Soleil. So you end up spending the next six months writing massive amounts of JavaScript code that will hardcode the customer’s process deep into the user interface. You will be late, over budget, and won’t benefit from future software upgrades, for what you have now is built upon a completely different codebase. Great…
The two things I want to call out are Lori’s phrase “orchestration of applications” and Ismael’s laments about the quality of the user interface. I believe both of these posts are hitting on an element that is frequently forgotten around SOA, which is the human interaction. Regardless of how many services you build, some user is still going to need a front end, and there are inherently different concerns involved. Ismael’s absolutely right that some bare bones web form creation tool slapped onto the ugly schemas that represent the process context just don’t cut it. While 5-10 years ago, you may have been able to limp by with basic HTML forms, today’s web UIs involve AJAX, CSS, JavaScript, Flash, and much more. The tools that are calling themselves orchestration engines excel at what Lori calls orchestration of services (the BPEL space), but I don’t know that there are many that are really excelling at business process orchestration. I’m using my definition of business process orchestration here, which is both the human activities and the automated activities. I’m guessing that this is what Lori meant by orchestration of applications, however, I try not to use the term application anymore. It implies a monolithic approach where everything is owned end-to-end, and that simply won’t be the case in the future. If I do use the term, it’s reserved for the human facing component of the technology solution.
True business process orchestration that includes the human element, is not one that we’re seeing a lot of case studies on, but it’s where we need to set our sights. The problem is quite difficult, as the key factor is context. When I was working with a team on a reference solution architecture for BPM technology, one of the challenges was how and when to bring in context. If you rely on events to trigger state transitions, should those events carry references to information, or the contextual information itself? If it contains references, then you need access to all of the associated information stores, and you need to figure out what information is relevant for the problem at hand. It’s hard enough to get this right for an automated system where the information required is probably well defined. Now try getting it right when the events are tied back to a user interface. The problem is that every scenario may require a different set of information. As humans, we’re good at determining correlations and understanding where to go. Systems are not. Our goal should be to creating solutions that support the flexible context required for true business process orchestration. I think this will keep many of us gainfully employed for years to come.
Uptake of Complex Event Processing (CEP)
I’m seeing more and more articles about complex event processing (CEP) these days. If you’ve followed by blog, you’ll know that I’m a big fan of events, so I try to read these when they come across my news reader. One of the challenges I see, however, is that event-driven thinking is not necessarily the norm for businesses. Yes, insurance companies may deal with disaster events, and financial services companies may deal with “life” events like weddings, births, kids going to college, but largely, the view is very service-based. It is reactionary in nature. You ask me for something, and I give it to you.
This poses a challenge for event processing to gain mindshare. While event processing is certainly the norm in user interface processing and embedded systems, it’s not in your typical business IT. Ask yourself- if you were to install a CEP system in your enterprise today, what events would it see?
The starting point that I see for events should merely be publication. Forget about doing anything but collecting statistics at the beginning. Since events don’t align with how we’re normally thinking, perhaps we should let them show us how we should be thinking. This gets into the domain of business intelligence. The beauty of events, however, is that they can make the intent explicit, rather than implicit. If I’m only performing analysis based on database changes, am I seeing the right thing, or am I only seeing symptoms of the event? Not all events may result in a database change, and that’s where the important correlations may lie. If some companies shows up on page one of the Wall Street Journal, it could result in increased trading activity for that company. My databases may record the increased trading, I may not have a record of the triggering event- the news story.
Humans are very good an inferring relationships between events, sometimes better than we think. But without any events, how can we infer any relationships? We don’t want to overwhelm the network with XML messages that no one ever looks at, but we shouldn’t be at the opposite extreme either. Starting with new applications, I’d make sure that those systems are publishing some key events based upon their functionality. Now, we can start doing some analysis and looking for correlations. We then start to encourage event-driven thinking about the business, and as a result, have now created the potential for CEP systems to be used appropriately.
As an example of how far we still have to go, let’s look at Amazon. They certainly leverage business intelligence extremely well. Unfortunately, as far as I can tell, it’s largely based upon tracking the event that impacts their bottom line directly- purchasing. If I were them, I’d be looking at wish list activity much more strongly. Interestingly, my wife gets more recommendations on technical books that I do. Why? Because she’s purchasing them as gifts for me. I put them on my wish list, she buys them. Because they’re looking at the wrong event, they now make an inference that she’s interested in them when she isn’t. I am. They need to track the event of me adding it to my wish list, along with someone purchasing it for me, and then turn around and make recommendations back to me. Of course, that’s part of the challenge, though. There is simply a ton of information that you could collect, and if you collect the wrong stuff, you can waste a lot of time. Start with a small set of information that you know is important to your business and build out from there.
SOA Maturity Model
David Linthicum recently re-posted his view on SOA maturity levels and I wanted to offer up an alternative view, as I’ve recently been digging into this subject for MomentumSI.
Interestingly, Dave calls out a common pattern that other models he’s seen define their levels around components and not degrees of maturity. He states:
While components are important, a maturity model is much more important, considering that products will change over time…
I completely agree on this. Maturity is not about what technologies you use, it’s about using them in the right way. Comparing this to our own maturity, just because you’re old enough to drive a car, doesn’t mean you’re mature. Just because you’ve purchased an ESB, built a web service, or deployed a registry doesn’t mean you’re mature.
Dave then presents his levels. I’ve cut and paste the first sentence that describes each level here.
- Level 0 SOAs are SOAs that simply send SOAP messages from system to system.
- Level 1 SOAs are SOAs that also leverage everything in Level 0 but add the notion of a messaging/queuing system.
- Level 2 SOAs are SOAs that leverage everything in Level 1, and add the element of transformation and routing.
- Level 3 SOAs are SOAs that leverage everything in Level 2, adding a common directory service.
- Level 4 SOAs are SOAs that leverage everything in Level 3, adding the notion of brokering and managing true services.
- Level 5 SOAs are SOAs that leverage everything in Level 4, adding the notion of orchestration.
While these levels may be an accurate portrayal of how many organizations leverage technology over time, I don’t see how they are an indicator of maturity, because there’s nothing that deals with the ability of the organization to leverage these things properly. Furthermore, not all organizations may proceed through these levels in the order presented by Dave. The easiest one to call out is level 5: orchestration. Many organizations that are trying to automate processes are leveraging orchestration engines. They may not have a common directory yet, they may have no need for content based routing, and they may not have a service management platform. You could certainly argue that they should have these things in place before leveraging orchestration, but the fact is, there are many paths that lead to technology adoption, and you can’t point to any particular path and say that is the only “right” way.
The first difference between my efforts on the MomentumSI model and Dave’s levels is that my view is targeted around SOA adoption. Dave’s model is a SOA Maturity Model, and there is a difference between that and a SOA Adoption Maturity Model. That being said, I think SOA adoption is the right area to be assessing maturity. To get some ideas, I first looked to other areas, such as CMMI and COBIT. If we look at just the names of the CMMI and COBIT levels, we have the following:
| Level | CMMI | COBIT |
| 0 | Non-Existent | |
| 1 | Initial | Initial |
| 2 | Managed | Repeatable |
| 3 | Defined | Defined |
| 4 | Quantitatively Managed | Managed |
| 5 | Optimizing | Optimized |
So how does this apply to SOA adoption? Quite well, actually. COBIT defines a level 0, and labels it as “non-existent.” When applied to SOA adoption, what we’re saying is that there is no enterprise commitment to SOA. There may be projects out there building services, but the entire effort is ad hoc. At level 1, both CMMI and COBIT label it as “Initial.” Again, applied to SOA adoption this means that the organization is in the planning stage. They are learning what SOA is and establishing goals for the enterprise. Simply put, they need to document an answer to the question “Why SOA?” At level 2, CMMI uses “Managed” and COBIT uses “Repeatable.” At this level, I’m going to side with CMMI. Once goals have been established, you need to start the journey. The focus here is on your pilot efforts. Pilots have tight controls to ensure their success. Level 3 is labeled as “Defined” by both CMMI and COBIT. When viewed from an SOA adoption effort, it means that the processes associated with SOA, whether it be the interactions required, or choosing which technologies to use where, have been documented and the effort is now underway to extend this to a broader audience. Level 4 is labeled as “Quantitatively Managed” by CMMI and “Managed” by COBIT. If you dig into the description on both of these, what you’ll find is that Level 4 is where the desired behavior is innate. You don’t need to handhold everyone to get things to come out the way you like. Standards and processes have been put in place, and people adhere to them. Level 5, as labeled by CMMI and COBIT is all about optimization. The truly mature organizations don’t set the processes, put them in place, and then go on to something else. They recognize that things change over time, and are constantly monitoring, managing, and improving. So, in summary, the maturity levels I see for SOA Adoption are:
- Ad hoc: People are doing whatever they want, no enterprise commitment.
- Common goals: Commitment has been established, goals have been set.
- Pilot: Initial efforts are underway with tight controls to ensure success.
- Extend: Broaden the efforts to the enterprise. As the effort expands beyond the tightly controlled pilots, methodology and governance become even more critical.
- Standardize: Processes are innate, the organization can now be considered a service-oriented enterprise.
- Optimize: Continued improvement of all aspects of SOA.
You’ll note that there’s no mention of technologies anyway in there. That’s because technology is just one aspect of it. Other aspects include your organization, governance, operational management, communications, training, and enterprise architecture. SOA adoption is a multi-dimensional effort, and it’s important to recognize that from the beginning. I find that the maturity model is a great way of assessing where an organization is, as well as providing a framework for measuring continued growth. That being said, your ability to assess it is only as good as your model.
Integration, not convergence
I recently had the opportunity to discuss the positioning of SOA appliances and it caused me to revisit my convergence model, as shown here:
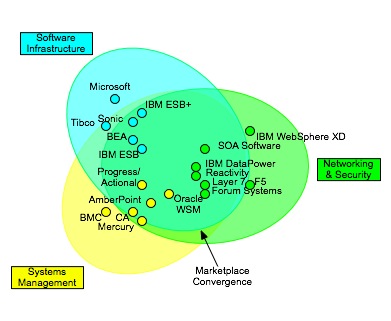
This diagram was intended to show the challenges that enterprise face in choosing vendors today, as there are solutions from multiple product spaces. The capabilities frequently associated with activities “in the middle” can come from network appliances, application servers, ESBs, service management systems, etc. My original post talked about the challenges that organizations face in trying to pick a solution. A key factor that must be weighed is the roles in the organization. My view is that the activities in the middle should beconfigured, not coded. That’s a topic for another post, however.
I started thinking about the future state, and realized that while the offerings from vendors overlap today, that shouldn’t be the long term trend. Even vendors that can cover the entire space do it with multiple products. The right model that we should be shooting for is one that looks like this:

In this model, we have four distinct components. Service hosting is concerned with the development and execution of services. Service connectivity consists of the capabilities in the middle: routing, mediation, etc. Service management provides management facilities over both of these domains. All of these systems rely on a set of information resources which provide both the information to process, as well as the policy and meta-information required for the appropriate execution of the systems. A registry/repository, therefore, would fall into the information resource domain.
What we’d like is for all of these domains to be integrated in an open, standards-based manner. Unfortunately, we’re still a ways off from that day. There have been some proprietary efforts to create integrated solutions that look like this, such as the Governance Interoperability Framework effort by Systinet, but there’s still a long way to go. None of the vendors associated with GIF are the big players in the service hosting space (IBM, BEA, Oracle, Microsoft, etc.), and the integration standards are not open. When we have open, integration standards, we can now begin to create the feedback loop.
One short-term issue that needs to improve is the tight coupling of management consoles to the platforms. In the model, service management is loosely coupled. It integrates with the other domains through loosely coupled services, all of the best practices of SOA. Today, service hosting platforms and service connectivity systems all come with their own management consoles. In order to enable this model, the management architecture of those systems must be built on SOA principles. That means that all of the capabilities that can be managed should be exposed as services. You want to deploy a new application to the application server? Call the application deployment service. This creates a great situation for automated build systems. Out of the box, the build process could be executed in your favorite BPEL engine, with controls for compilation, automated testing, source code tagging, and deployment all orchestrated through web service interactions. Now add in a feedback loop by which metrics cause additional provisioning, or even where an uncaught exception results in a tag being placed on the source files associated with the stack trace to aid in debugging. It all begins with having the services available. Ask your vendors one simple question: are all the capabilities available through the management console also available as services?
An answer to slum control
Vilas posted a response to some of the postings (here and here) I made regarding the relationship of city planning to EA/SOA. He provides an example of a business sponsor that promotes a program that can add million dollars to the bottom line, but has an extremely short timeline, one that requires the existing architectural guidelines, principles, and processes to be short-circuited, or more likely, completely ignored. He compares this effort to a slum getting developed in a nice city.
I’m not going to argue that this situation doesn’t happen. It does. What I will argue, however, is that the fact that it allowed to be built can be a case of ineffective governance. The governance policies and processes have to be about encouraging the desired behavior. If the policies and processes aren’t consistent with the desired behavior, it’s a case of bad governance. In this example, this is likely a rapid growth opportunity. If the enterprise as a whole is in a cost cutting mode, I have a hard time believing that this rapid growth scenario would pass the governance checks and be viewed as a “solid business case.” If the corporate leaders have decided that the best direction for the company is to cut costs, odds are that a project such as this will never make it out of the governance process to begin with. If the company is focused on increasing revenue and growth, odds are it has taken more of a federated governance model, and allows individual business units to make decisions that are in their own best interest, sometime introducing redundant technology in order to meet the schedule demands of the growth cycles. If the enterprise architects in this model are instituting technical governance that constrains that growth, again, they’re acting in a way that is inconsistent with the goals of the organization, a case of bad governance. In either case, that mismatch will eventually cause problems for the organization. In the case of city, it may bring in crime, lower property values, and cause prosperous businesses and their revenues to move elsewhere. In the business world, it could cause a lack of focus on core capabilities, cost overruns, and fragmentation within. None of these risks were probably included in the business plan.
This is the dilemma of the enterprise architect or really anyone with some authority in the governance process. Growth is usually something that is important and achievable in the short term, but difficult to sustain in the long term. Growth has to occur in other areas, while cost cutting measures must be introduced in the former areas. Cost cutting leading to the elimination of redundancy, and if the technology wasn’t planned for that eventual occurrence from the beginning, the effort to reduce costs may eat away any potential savings. This is where the service abstraction is extremely important. Correctly placed services can position a company to consolidate where appropriate down the road. It will pay benefits when a merger and acquisition must occur by providing an analysis point (the service portfolio) from both a business and technology perspective to better estimate the cost of the integration activities.
Upcoming Webinar on SOA Pilots
Alex Rosen and I will be giving a webinar next Friday on the role of pilots in achieving SOA success. I haven’t blogged on SOA Pilots in quite some time (March 23rd of last year, to be exact). It’s always interesting to go back and read some of my past posts to see how my thinking has evolved. I had quoted the ZapThink guys, as well as Miko Matsumura in that entry, stating:
Miko stated that the only ones getting it right were ZapThink, who state that “the things you do in a pilot are the exact opposite of what you need to do to get to enterprise scale.” For the record, I agree. This all comes down to defining the pilot properly. In their book, “Service Orient or Be Doomed!” Jason and Ron call out three SOA Pilot essentials: an architectural plan (the pilot will cover some portion of it), a specific scope, and clear acceptance criteria.
There shouldn’t be much controversy over these, but yet, the case studies and whitepapers that I see presented don’t have these elements, and it’s usually because the study is equating web services usage with SOA. Taking a user-facing customer portal and extending it by allowing customers to integrate their systems directly can be a good thing, but is it really an SOA pilot?
I went on in the entry to lock in on the subject of culture change, stating: “a proper SOA pilot is to pick a problem that will require the organization to see the cultural changes that are necessary to become a service provider.” I still think that this is the case, however, I would also say that I was being just as narrow as the teams that strictly focus on using Web Services for the first time.
What you’ll find in the webinar is that SOA adoption involves many dimensions. One of those dimensions is technology based. Another dimension is cultural. I’ve been working with my colleagues on a maturity model that outlines these dimensions and the stages that an organization goes through across all of them. Pilot efforts should cover all of these. It may be done in one large program, or there may be several pilot projects. Every organization is different, therefore, there is not a one size fits all project that every organization should embrace.
If this sounds interesting to you, then I encourage you to sign up here, and listen in on Friday the 16th, at 1pm Eastern Time (Noon central, 10AM Pacific).
Your next task on the apprentice…
I want to turn on Donald Trump next Sunday night and see him task the teams with the successful creation and marketing of SOA within an enterprise. Okay, so it can’t be done within the day or two that they normally have, and outside of some Dilbert-esque quotes, it probably wouldn’t make for good TV. What it would do, however, is allow IT to see what their culture needs to be like in the future.
There’s a discussion just getting started in the Yahoo SOA group that raises some questions about the importance of marketing in SOA. A frequent complaint in the boardroom on “The Apprentice” is that the marketing strategy didn’t cut it and as a result, the person responsible for marketing on that task is fired. IT isn’t made up of bunch of people with MBA’s from Harvard, Wharton, or even Trump University. I have two degrees from the College of Engineering at the University of Illinois. During my stay there, I was not required to take any marketing courses, although the Computer Science department did require students in their undergraduate engineering program to take 4 courses outside of the department (independent of other electives) to which CS could be applied. The most popular area was business, with my choice, psychology, being second. The typical techie does not have formal training in marketing or other aspects of running a business, so it’s no surprise that we have a hard time with it.
We need to bring some business savvy into the IT department. I’m not talking about an understanding of the business being supported by IT (although that’s important too), I’m talking an understanding of how to succeed in business. Marketing, sales, product development, research, etc. A service provider needs to think of themselves as a vendor. They need to have a customer centric focus, with an understanding of the market trends (i.e. the business goals), customer needs, product lifecycles, resource availability, etc. to be successful. IT cannot simply be order takers in the process, because technology usage within an enterprise is not a commodity. The business side can’t simply go to IT Depot at the nearest shopping zone and pick up what they need. There are elements of technology that can be, and this will continue to fuel SaaS and other managed services, but here and now, the need for the IT department still exists. It’s time to change the IT culture, and get the development teams thinking about Service Management and a more business-like approach to their efforts.
Update: While the whole idea of bringing MBAs in was somewhat in jest, this is exactly what IBM did. Joe McKendrick’s eBizQ SOA in Action blog brought it to my attention, here’s a link to the original eBizQ story.
